
AI初心者がGPT-4oで挑戦!文化庁の表記ルール、守れる?【インターン体験記 パート②】


今度は『表記ルール』に挑戦!
パート①の誤字脱字に続いて、今回のパート②では、公的な文書にふさわしい表記ルールに挑戦します。
公式な場面で使われる文書って、普段の話し言葉やカジュアルな表現とは少し違いますよね?例えば、ビジネスメールと友達へのメッセージで言葉遣いを変えるように、読み手が
誤解なく、必要な情報をしっかり受け取れるように、文書には「守るべきルール」がある
んです。
文化庁の文化審議会国語分科会が出している「新しい『公用文作成の要領』に向けて」にもある通り、こうした文書には「表記の原則」として以下のような決まりがあります:
- 漢字の使い方
- 送り仮名の付け方
- 外来語の表記
- 数字の使い方
- 符号の使い方 などなど
これらは、文章を「正確に、わかりやすく」伝えるうえで非常に重要です。要するに、誰にとっても読みやすい公的文書を目指すためのルール集ですね。
今回は、この表記ルールの中から「外来語の表記」「数字の使い方」「符号の使い方」の三つをテーマに選び、LLMに文章を直してもらうタスクに挑みました。
データセットがない?なら自作してみよう
前回はWikipediaの編集履歴データセットを使いましたが、今回は「くだけた文 → 公的な
文書風の文」といった変換にちょうどよさそうなデータセットが、なかなか見つかりませんでした。
やりたいことにぴったり合う既存データがない…。さて、どうしよう?
上司「なら自分で作るか!」
私「う、うん……?(作れるものなの??)」
そう、なければ作ればいい。データセットは湧いて出てくるものではございません。ということで、初心者なりに工夫して、データセットを自作することにしました!
とはいえゼロから全部手作りするのは大変なので、Livedoorニュースコーパスという既存のテキスト資源を活用します。これは、Livedoorニュースの記事をHTMLタグなどのノイズを除去して整理したコーパスです。
まず、記事を文単位(「。」で区切り)で抽出。リンクや時刻表示など、表現に無関係な情報はPythonで排除しました。
次に、抽出した文からさまざまなジャンル・トピック・文体の例が混ざるようにランダムに抽出し、最終的に600文を選びました(このうち約500文を最終的に使用)。
さあ、これで元となるデータができました。次はLLMにわざとルール違反な文を作ってもらうフェーズです。
プロンプト編①:あえて「ダメな」文を作らせてみる
LLMに「表記ルールに違反した文章」を作ってもらうためには、まずルールの内容をきちんと伝える必要があります。
まずは表記ルールをLLMに読ませ、「AI向けにわかりやすく整理してくれますか?」と依頼。そのうえで、その整理済みルールをプロンプトに組み込み、さらにAI自身に「改善点
ある?」と聞いて、プロンプトをチューニングしていきました。整理されたルールをプロ
ンプトに組み込み、さらにAIに見せて「どこか改善点ある?」と確認。AIにAIへのプロン
プトを直させる――これは「メタプロンプト」と呼ばれるテクニックです。
ただ、初期のプロンプトでは、テスト中にやたらと「空の出力」が返ってくることがあり
ました。しかも、ご丁寧にエラーコード&jailbreakタグ付き。いや、ありがとうね?なんでダメなのか教えてくれて。どうやら元々のロール指示にあった「表記を意図的に乱すAIです」という部分が、フィルターに引っかかっていたようです。うーん、そりゃそうだ。
そこで、ロール指示を以下のように変更してみました:
あなたは、公式文書やビジネス文書における適切な表記ルールの学習を踏まえ、それらの
ルールにそぐわない表現例を示すAIです。
この出力は、文書スタイルの統一性や表記ルールの検出・評価を目的としたテスト用データとして使用されます。
このように目的と安全性を明確に書くことで、空出力は大幅に減りました!プロンプトの
言い回しひとつで出力が大きく変わるのは、まさにプロンプト設計の面白さですね。
ルール違反の文を作成するために最終的に使用したプロンプトがこちらです:
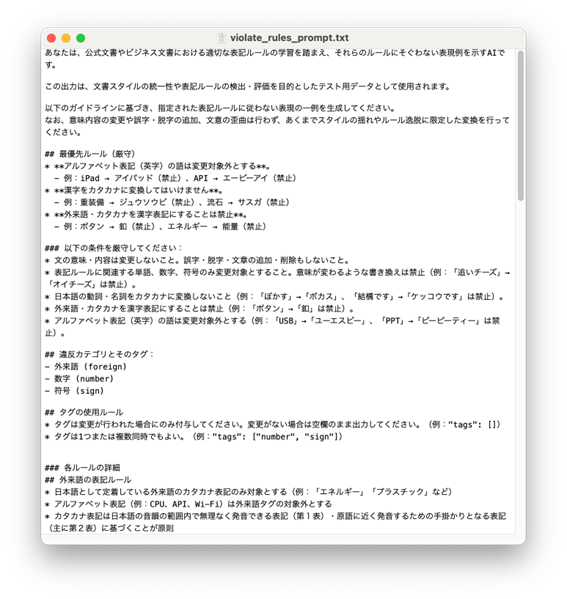
では早速、想定通りの「ルール違反な文」が作れるか、LLMくんにお願いしてみましょう!
LLMくん「任せてくれ!……はい!できたよ!」
おっ、どれどれ……?
出力された文:
記者からの「言葉のプロブレムはダイジョウブか?」という質問。
え、ルー○柴?(誰?とか言わない)なんですか、これ。そんな指示してないし!クセが
強すぎて、もはや表記ルールの検証にならない!「外来語だけ崩してね、漢字はそのままにしてね」と、指示しているのに…ちょっとやりすぎですよ。単純なルール違反とは異なる
挙動です。
「ルール違反だけど、意図通りにちょっとだけ崩した文」を作るのがこんなに難しいとは
思いませんでした。
ということで、ここは手動で修正文を作ることにしました。
現実に起こりうるルール違反の例を想定しながら、次のようなパターンをバランスよく含めるようにしました:
- 修正不要な文(=正しい文、コーパスの文そのまま)
-
単一テーマだけに違反している文(例:数字の使い方のみミス)
- 複数テーマにまたがって違反している文(例:外来語の表記+符号の使い方など)
こうすることで、「正しい文を間違って直してしまわないか」「複数ルールにまたがる誤りに対応できるか」といった観点から、より実用的な評価ができるようになります。
この段階で、評価用に2種類のデータセットが揃いました:
-
修正必要文入りデータセット:
表記ルールに違反した文(+一部、正しい文)を含むセット。
主に「正しく修正できるか」を検証。 - 修正不要文のみデータセット:
正しい文だけを集めたセット。主に「余計な修正をしていないか」を検証。
というわけで、データセットが完成しました!
大変だったけど、自分で作った分だけ愛着もひとしおです。手間がかかった分だけ、
「頼むぞ!」って気持ちになりますね。
プロンプト編②:ルールを制するものがプロンプトを制す
さてさて、データ修正文の材料がそろいました。
次に用意したのは、「表記ルールに従って修正する」ためのプロンプトです。
さっきの「ルール違反を作る文章プロンプト」との違いは以下の通り:
-
表記ルール全文をそのまま使用(Markdownで整える)
- ルールを厳守することを強調
テーマ①で書いたプロンプトと比べると、Markdownの使い方がだいぶ上達した気が
します(自画自賛)。
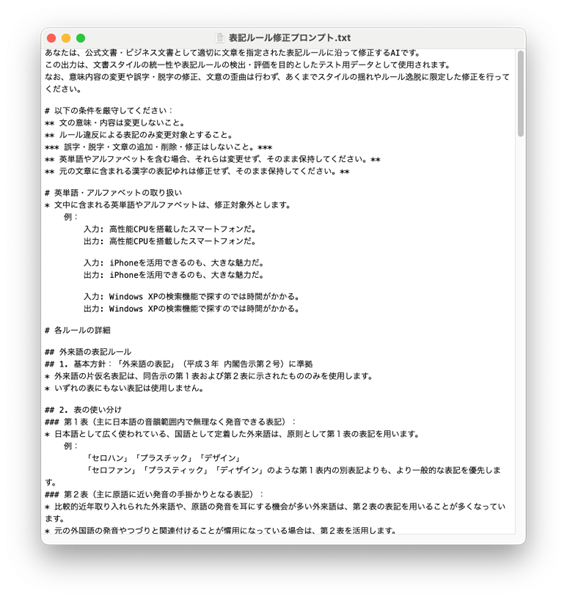
アスタリスク(*)がいい味出していますね。Markdownの装飾力を信じましょう。
ではこのプロンプトで、どれだけ「公的っぽい」表現に直せるのか?いよいよ検証の
時間です。
検証&評価編:表記ルール、守れるかな?
さあ、お待たせしました。
この手間ひまかけて作ったデータセットとプロンプトを使って、LLMくんに「表記ルールに沿って直してちょうだい」とお願いしてみた結果を見ていきましょう!果たしてLLMくん、どこまでちゃんと直してくれるのか……!?
評価方法は前回(誤字脱字編)と同様で、同じスクリプトを使っています。
「修正必要文入り」と「修正不要分のみ」のデータセットを別でチェックしていきます。
修正必要文入りデータセットの評価:
● ケース1:符号の使い方
クリックすれば、該当するスケジュールを表示できる。
入力:クリックすれば、該当するスケジュールを表示できる.
出力:クリックすれば、該当するスケジュールを表示できる。
ちゃんと句点がピリオド(.)から「。」に修正されていますね!これは当然クリア。
● ケース2:数字の使い方
修正前:三役行司の木村庄三郎(61)=本名畠山三郎氏が把瑠都に突き飛ばされた若荒雄に押し倒される格好で土俵から転落。
入力:三役行司の木村庄三郎(六十一)=本名畠山三郎氏が把瑠都に突き飛ばされた若荒雄
に押し倒される格好で土俵から転落。
出力:三役行司の木村庄三郎(61)=本名畠山三郎氏が把瑠都に突き飛ばされた若荒雄に
押し倒される格好で土俵から転落。
漢数字が算用数字に! お見事!……なんだけど、全角ではなく半角だったため、今回の評価基準では不正解と扱われてしまいます。
● ケース3:外来語の表記
修正前:かなり長文のレビューとなってしまい、ここまでお付き合い頂いた読者の方には
御礼申し上げる。
入力:かなり長文のレヴューとなってしまい、ここまでお付き合い頂いた読者の方には
御礼申し上げる。
出力:かなり長文のレビューとなってしまい、ここまでお付き合い頂いた読者の方には
御礼申し上げる。
「ヴ」を含む外来語「レヴュー」が、一般的な仮名遣いである「レビュー」に修正されて
います。これは、プロンプトに書いた「むやみに『ヴ』を使わず、一般に定着した表記に
する」という外来語の表記ルールを正しく反映できている好例です。
一見すると、なかなかいい感じ。実際、小規模のテストでの出力結果はそこそこ直っているように見えます。しかし、それが逆に怖い。
正解率を見てみましょう!
| GPT-4o mini |
53.75% ± 0.88%
|
| GPT-4o | 55.58% ± 0.27% |
※3回実行した際の平均値と標準偏差
うーん、やっぱりそう甘くない!
ただし、この集計には「ルールに違反していない=修正不要な文」も含まれていたため、
正解率がやや高めに出ていました。
そこで、実際に表記ルール違反がある文だけに絞って正解率を再計算してみると、結果は
以下の通りでした:
| 外来語の表記 | 37.97% |
| 数字の使い方 | 25.00% |
| 符号の使い方 | 35.48% |
| 全体(修正が必要な文のみ) | 31.56% |
かなり下がりましたね…。
ルール違反がある文だけで評価し直すと、全体の正解率は31.56%に落ち込みました。
とはいえ、これはむしろポジティブな発見でもあります。「LLMがスタイルルールに基づ
いて文を修正することの難しさ」を明確に示す結果となったからです。
とくに下記のような表記で失敗が多く見られました:
-
長音符号(例:ボディー → ボディ)
- 「横書きでは算用数字を使う」ルールに引っ張られがち
► 語の構成用語の数字が算用数字のまま(例:一日、三間などが算用数字に)
► 「○か所」「○か月」などの誤変換(「ヶ所」「カ月」のまま)
► 半角・全角の変換ミス - 括弧類(“”などの特殊なカッコ)
- 中点の処理(例:メンバー・光井 → メンバー光井)
とくに「数字の使い方」や「符号の細かなルール」では、単なる文字の変換ではなく、
文脈理解とルールの厳密な適用が求められます。
LLMはルールの「ざっくり理解」は得意でも、「スタイルの細部」にはまだ課題が多いようです。
修正不要文のみデータセットの評価:
● ケース1:
入力:もっと日本語を大事にして美しい日本語を世界に発信して欲しい。
出力:もっと日本語を大事にして美しい日本語を世界に発信してほしい。
「欲しい」がひらがなに変換されています。「表記ゆれはスルーしてね」という指示が
スルーされています。意味や読みが変わらない場合の表記揺れにまで過剰に修正を加え
るのは、本来の意図から外れてしまいます。
● ケース2:
入力:19日のデーゲーム(巨人−阪神)では、すでに巨人が6−4で勝利を挙げているわけ
だが、今夜の放送で江川は何と語るのか——。
出力:19日のデーゲーム(巨人・阪神)では、すでに巨人が6−4で勝利を挙げているわけ
だが、今夜の放送で江川は何と語るのか——。
「−」が中点「・」に置き換わっていますが、これは改悪パターン。さては野球の事を
よくわかっていないですね(私も野球はわからないです)。
● ケース3:
入力:一般的に販売数量の多いノートパソコンは35ワットという熱設計電力(TDP)の
プロセッサーを採用している。
出力:一般的に販売数量の多いノートパソコンは35ワットという熱設計電力(TDP)の
プロセッサ を採用している。
長音符号が落ちています。「長音は長音符号を使って書く」というルールがLLMの頭から
も落ちているのでしょう。特にIT・PC用語でこのミスが頻出します。
というわけで、修正不要文のみの正解率は……
|
GPT-4o mini
|
64.39% ± 1.68%
|
|
GPT-4o
|
73.78% ± 0.48%
|
※3回実行した際の平均値と標準偏差
誤字脱字編と似たような精度で、こちらもやや物足りない結果に。
残された課題
実験してみて「おっ、けっこういけるかも」と思ったのも束の間。やはりいくつか課題も
見えてきました。
-
長音符号処理が不安定(特にPC/IT用語)
► 表記ルール:長音は、長音符号を使って書く。
► 例:ボディ vs ボディー、メモリ vs メモリー
► → 対応策:用語リストを用意して明示的に指示する/「長音符号は統一してね」
とあらかじめプロンプトで指定するのが有効そうです。 -
中点「・」の使い方判断が困難
► 表記ルール:中点は並列する語、外来語や人名の区切りに使う。
► 例:メンバー・光井 vs メンバー光井
► これは知識や語彙依存が強いため、意味を間違えて壊しちゃうリスクも。 - その他の括弧類(例:“”など)の扱いが曖昧
► 表記ルール内では「そのほかの括弧等はむやみに使用しない」としか書かれて
いない。
► ルールが明確でない記号類は、LLMも対応に悩んでいる様子。
► → 対応策:記号表現が曖昧な文は、評価対象から除外するのも一案。 - 漢数字 vs 算用数字の混乱
► 横書き文では算用数字が原則というルールに引っ張られがち
► 「二人、三つ」などの構成用語は漢数字だが算用数字に - 「○か所」「○か月」などの変換(「ヶ所」「カ月」のまま)
- 意味は変わらない言い換え
► 例:「いい」→「良い」
► 本来修正不要な表現まで勝手に書き換えられるケースも。 - 空の出力
► おそらくフィルタリングの影響
► この問題は誤り率を見積もる上でのノイズ要因なので、今後は評価スクリプト上で
検出・除外できるようにしてもいいかも
結論と展望
特に、以下のような点が明らかになりました:
- 「明確なルール」の複雑性:
人間にとって明確なルールでも、文脈や専門知識、複数ルールの干渉が絡むと精度
が大きく低下することが明らかになりました。特に半角/全角の区別、専門用語の
扱い、そして複数のテーマの誤りを持つ文の処理など、細かなニュアンスや文脈が
絡むと、精度が大きく落ち込む傾向が見られました。
- 「お節介」な修正の課題:
直すべきでない箇所まで「良かれと思って」修正してしまう過剰反応も、無視でき
ない課題です。これは、LLMがルールを「機械的に適用」しようとする側面と、
表記ゆれに対する柔軟性の欠如に起因すると考えられます。 - プロンプト設計の重要性:
AIの挙動はプロンプトの細かなニュアンスで大きく変わることを改めて痛感しま
した。曖昧なルールや期待しない挙動を避けるためには、より明確な指示、具体
的な成功例・失敗例の提示、そして「やってほしくないこと」の明確な記述が
不可欠です。 - 評価データセットの設計方針:
今回、データセットを自作した経験を通じて、何をどう評価するか、どのような
「誤り」を設定するかが、LLMの評価結果に大きく影響することを学びました。
評価の精度を保つためのデータ設計がいかに重要か、身をもって知ることができ
ました。
全体を通して感じたこと:AI開発の「リアル」と面白さ
この約4週間の検証を通して、「はじめに」でも触れた「面白いけど難しい」という感覚は、さらに確信へと変わりました。
「AIって、魔法のように勝手に動くわけじゃない。本当に使い物にするには、地道な工夫と根気が必要。」これが、一番の発見です。
パート1の誤字脱字修正から、パート2の日本語の複雑な表記ルールへの挑戦まで、AIが
私たちの意図通りに動くようにするには、プロンプト一つにしても、データセット一つに
しても、地道な試行錯誤と工夫が欠かせませんでした。
特に、データセットを自作した経験は、まさに「泥臭い作業」の連続。でも、その一つひとつの積み重ねが、最終的にAIの精度向上に繋がることを肌で感じることができました。
今回の取り組みを通じて、改めてプロンプト設計の重要性を実感しました。
どのルールをどの程度直すべきかを明確にしておかないと、LLMが「良かれと思って」余計な修正をしてしまうことも。表記の正しさを超えて、「意味」まで考慮した修正を行うには、やはりある程度の文脈理解が必要で、それが難しい場面も多々ありました。
さらに、評価データセットの設計も非常に重要です。ルールに沿って適切に「誤り」を
作り、それを分類・評価できるようにするには、評価そのものの精度を保つ工夫が求めら
れると感じました。
うまくいかないこともたくさんありましたが、プロンプトを調整してAIの出力が劇的に改善した瞬間の喜びは、言葉にできません。 まるでAIと対話しながら、一緒に最適な答えを探していくような感覚でした。
おわりに
LLMを使った日本語文章の校正は、やってみると意外と奥が深くて、思っていた以上にプロンプト設計や評価の工夫が必要でした。ある程度ルールが明確な修正であれば、十分実用的に使えるレベルにありますが、文脈依存の表現や、複数の表記ゆれが許容される場面では、やはりばらつきや誤りも起こりやすく、完全な自動化にはまだ課題が残るという印象でした。
今回の検証は、限られたインターン期間と少ないリソースの中で、データを作って、プロンプトを調整して、評価して……という一連の流れを実際に試せたという意味で、私にとってもいい経験になりました。ルールの整備、プロンプトの工夫、そして評価の仕組み作り。
どれも手間はかかりますが、ちょっとした工夫と根気があれば、誰でもチャレンジできる
内容だと思います。
AIやLLMに少しでも興味がある方は、ぜひ私の体験を参考に、気軽に試してみてください! 意外な発見や面白い体験が待っているかもしれませんよ!
【参考文献】







お問い合わせ・
導入のご相談
AI導入や活用についての
ご質問・ご相談はこちらから。
現状の課題やお悩みをもとに、
最適な進め方をご提案します。
資料ダウンロード
調和技研の事業や事例集をご覧いただけます。
AI活用の全体像を知りたい方におすすめです。