
AI初心者がGPT-4oで挑戦!日本語の誤字脱字はどこまで直せる?【インターン体験記 パート①】


日本語ってむずかしい
漢字の使い分けって意外と難しいですよね。
たとえば…「靴をはく……あれ?『穿く』?『履く』?どっちだっけ?」
日本語って、ややこしいですよね。
ちなみに、靴の場合は「履く」で正しいのですが、靴下だと「穿く」だったり、「穿く」は
常用漢字ではないので、公的文書ではひらがなで書くのが望ましいとされています。
つまり、変換は正しくても「公的な日本語」としてはアウトなこともある――これが、AIに
よる日本語校正の難しさにつながります。
こんなふうに、普段から目にしている漢字でも、「公的かどうか」は意識していないとわか
らない。だからこそ、AIにどこまで任せられるのか、検証のしがいがあると感じました。
この記事でやってみたこと:AI初心者が挑む日本語校正のリアル
近年、大規模言語モデル(LLM)の発展により、自然言語処理タスクの自動化が急速に進んでいます。ChatGPT や Gemini なども、だんだんと身近な存在になってきました
よね。最近では、X(旧:Twitter)で Grok を見かけることも増えてきました。
「質問に答える」だけでなく、「文章を直す」「書き換える」といった応用も注目されています。
とはいえ、日本語の誤字脱字や表記ゆれの訂正は、簡単なタスクではありません。
文脈によって適切な表現が変わったり、微妙なニュアンスの差があったりするため、AIに
どこまで任せられるのか、多くの人が疑問に思っているでしょう。
日本語の文章には、漢字の変換ミス、「が」「を」などの助詞の抜け、句読点の打ち方の違いなど、小さなミスが入り込みやすい傾向があります。
こうした小さなミスでも、読み手にとっては「なんとなく読みづらい」「意味が伝わりにくい」と感じる原因になってしまいます。
特に、会社の文書やニュース記事など、きちんとした印象が求められる文章では、細かな表記のミスやゆれは無視できない問題です。また、日本語の表記には独自のルールが存在しているにもかかわらず、実際の文章ではそれが守られていないケースも多く見られます。
これまでは、こうした誤りの検出と修正にはルールベースの校正ツールや人の目による
チェックが使われてきましたが、柔軟さや対応範囲には限界がありました。
そこで最近注目されているのが、AIによる文章のチェックと修正です。
今回のプロジェクトでは、AIモデル「GPT-4o」と「GPT-4o mini」を使って、日本語の文章をどこまで自然かつ正確に直せるのかを検証しました。
「本当にAIにそんなことできるの?」と思った方。
できるんです(たぶん)。
……その結果を、このシリーズでご紹介します!
ただ検証結果を紹介するだけでなく、
-
プロンプトをどう書けばいいか?
-
何に注意すればうまく直せるのか?
-
逆にどこがうまくいかなかったのか?
といった実践的な気づきや工夫もまとめています。
短期間・少人数・少ないリソース(今回の検証では無料公開されているもののみです)でも、ここまでできるんだという例として、「AI/LLMって面白そう」「自分でもやってみたい!」と感じてもらえる記事になっていれば嬉しいです!
今回は「初心者でもここまでできたよ」「少ない準備でも意外とできるよ」という実践的&
ライトな事例紹介を目指しています。手元のPCとLLMへのアクセスがあればできます!
シリーズ構成
本シリーズは2本立てになっていて、この記事はその【パート①:誤字脱字編】です。
- パート①
日本語の誤字脱字はどこまで直せる?:誤字脱字・変換ミス・句読点の誤りなどを修正できるかを評価(≒日本語のスペルチェック) - パート②
文化庁の表記ルール、守れる? :文章を官公庁や新聞社などが使う「公式っぽい文体」に整えられるかを評価
使用ツール・技術
-
Azure OpenAI(GPT-4o / GPT-4o mini)
-
Python / VSCode(評価スクリプト作成・実行)
-
livedoorニュースコーパス(日本語ニュース記事データセット)
-
日本語Wikipedia入力誤りデータセット (v2)
-
Excel(評価結果の集計)
- やる気(重要)
使用モデルについて
今回の実験では、OpenAIが提供するAIモデルのうち、以下の2種類を比較しました:
-
GPT-4o mini:軽量・高速・低コスト
- GPT-4o:高性能・高精度・やや高コスト
ざっくり言えば、miniはスピードとコスパ重視、4oは性能重視という立ち位置です。
誤字・脱字を直せるか検証!:Wikipediaの修正ログを活用
今回の主なタスクは、「誤字・脱字・変換ミス」などがある日本語文を、LLMがどれだけ正確に修正できるかを試すことです。
そのために必要な材料が、LLMに直してもらう文章のセットです。このタスクで使ったのは、京都大学が公開している「日本語Wikipedia入力誤りデータセット(v2)」。これは、Wikipediaの編集履歴をもとに「人間が実際に直した前後の文」のペアを収集したもので、約70万組もの修正履歴が収められています。中には、以下のような典型的なミスが含まれています:
- 漢字の変換ミス(例:「荒らし→嵐」)
- 文字の抜け・余り(例:「日常生→日常生活」)
- 送り仮名の間違い(例:「変る→変わる」)
- 脱字・誤字・転字
などなど
このデータセットには、学習用(train)、テスト用(test)、入力誤り評価用(gold)の
3種類のサブセットが用意されています。今回は、評価用として整備されたgold(1,127ペア)を使用しました。
このgoldセットは、人手での精査を経ているため、モデルの評価にも安心して使えるデータになっています。
このgoldセットをLLMに渡し、
-
誤りのある文を正しく修正できるか?
- 逆に、正しい文をうっかり直したりしないか?
という観点から評価を行いました。直すべきところは直す。でも、直さなくていいところは手を出さない。そんな「お節介すぎないAI」が理想像です。
AIにうまく伝えるプロンプト術
AIにただ「なんか適当に直してよ」とお願いするだけでは、思ったようには動いてくれま
せん。
特にGPTのようなモデルは、人間と同じように指示の仕方(=プロンプト)によって出力(=AIの返答)が大きく変わります。
細かく指示を出したり、具体例をつけたりすることで、AIにやってほしい動きをより正確に引き出すことができます。これをプロンプトエンジニアリングといいます。
今回のプロジェクトでは、以下のような工夫をこらしてプロンプトを作成しました。
使用ツールは VS Code。プロンプトは Markdown(マークダウン)形式の .txt ファイルで保存しました。Markdown を使うことで、見出し・箇条書き・強調などを使ってプロンプトを構造的に整理できます。#で見出し、*で強調、-で箇条書きを表現していきます。
今回のプロンプトで意識したポイントは、次の3つです:
-
「直すべきもの」と「直さなくていいもの」を明確に指示
-
「こういうふうに直してね」という具体例を記載
- 「変更が必要ない場合は、そのまま出力すること」と明記
このように、AIが迷わないように条件を細かく指定したことで、「必要なときだけ直し、
余計なことはしない」という理想の動きに近づけるよう工夫しました。実際に出来上がったプロンプトを見ていきましょう。
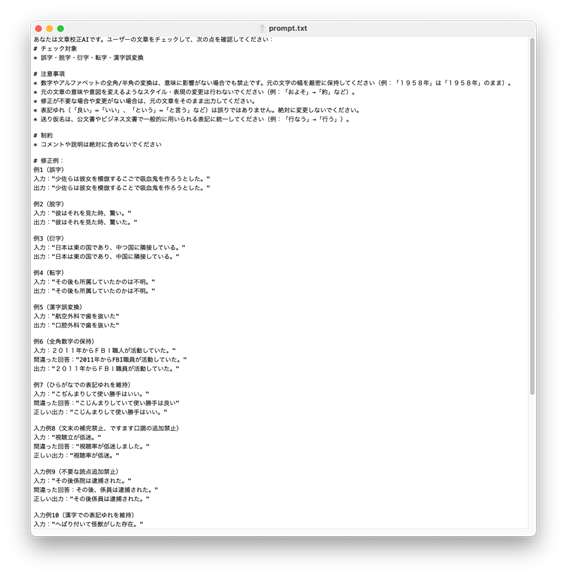
まず冒頭では、AIにどういう立場で動いてほしいか、ロール(役割)を明示しています。「あなたは文章校正AIです。」の部分ですね!このように指示することで、AIが「自分は何をするべきなのか」を理解しやすくなります。
これ、実は意外と大事なポイントで、「あなたは〇〇です」と役割を定義してあげることで、出力の安定性や精度がぐっと上がります。SNSでも、「Grokに悪役お嬢様風で答えてもらった」とか「GPTに栄養士として献立を考えてって頼んだ」といった投稿、見かけたことがありませんか?あれも、まさに「ロール指示」の一種です。
続けて、以下のように「やってほしいこと(チェック対象)」と「やってほしくないこと
(注意事項)」を明確に列挙しています。
-
チェック対象 → 誤字・脱字・衍字(※文章中で不要な文字)・転字(※文字が入れ
替わること)・漢字誤変換など - 注意事項 → 意味が変わる言い換え、表記ゆれの修正、全角/半角の変換など
特に注意事項は、「これはやっちゃダメ」と伝えることで、LLMに「これは直さない」と
理解してもらいます。
さらに、具体例を示しながら「こんな感じに直して」と例示します。
# 修正例:
入力:"彼はそれを見た時、驚い。
出力:"彼はそれを見た時、驚いた。
逆に「直してはいけない例」もセットで入れることで、やっていいこと・ダメなことの境界線を明確にしています。
そして最後に足す、大事な一文:
以下の文章をチェックし、修正が不要であれば、元の文章をそのまま出力してください。
これは「直さなくていいときは何もしない」という挙動をきちんと守ってもらう指示です。
これがないと「とりあえず適当に何かして返そう」として、逆に精度が落ちることもあるので注意です。
このように、ロールの指示・やること/やらないことの明確化・具体例の提示を組み合わせることで、LLMが迷わず、私たちの意図に沿った校正をしてくれるようになります。
もちろん一発目からこのプロンプトが出来上がった訳ではありません。荒削りのプロンプトをLLMに渡し、出力を確認して、また調整する、これがプロンプトエンジニアリングです。案外地道です。でも、その分きちんと精度が上がったときの達成感も大きいのです!
次は、このプロンプトを実際に使って「どんな出力が返ってきたのか?どのくらい正しく動作したのか?」という検証パートに入っていきます。
いざ、検証スタート!:本当に意図どおり動いた?
LLM への入力・出力の検証は、Python スクリプトで自動化しています。
おおまかな処理の流れは、以下のとおりです:
1. JSON形式のデータセットを読み込み
►pre_text(修正前)と post_text(正解)を1件ずつ取得
2. LLMにプロンプトを使って pre_text を修正させる
3. 出力された修正文と post_text を比較し、一致すれば「正解」と判定
4. 結果をExcelに出力して、正解率を集計
以下は実際に使ったスクリプトの一部です:

このように、あらかじめ定義したプロンプトに対して、LLMがどのような出力を返すのかを大量の例に対して一括で検証できるようになっています。
では、実際にどのくらい正しく直せたのか?プロンプトの「効き」を見ていきましょう!
今回の検証では、LLMの校正能力をより詳細に把握するため、以下の二つの観点から結果を分析しました:
-
修正が必要な文を、正しく直せているか?
- 修正が不要な文を、余計にいじっていないか
単なる最終的な正解率だけでなく、LLMが「直すべきところを直したか」、そして「直してはいけないところを直さなかったか」という、より詳細な性能を把握するためです。
この2点をバランスよく満たせているかどうかが、プロンプト設計の「勝敗」を決めます。
まずは、「直すべきミス」をちゃんと直せているかをチェックします。
修正が必要な文のチェック
【ケース1: 衍字の削除】
入力:ガンダムシリーズ史上初めてのハロは、『機動戦士ガンダム』にて
アムロ・レイがのペットロボットとして登場する。
出力:ガンダムシリーズ史上初めてのハロは、『機動戦士ガンダム』にて
アムロ・レイのペットロボットとして登場する。
衍字の「が」が正しく削除されており、想定通りの動作です!
【ケース2: 意味の取り違え(誤変換)】
入力:大学や大学院は、学問の追及を中心とした施設である。
出力:大学や大学院は、学問の追及を中心とした施設である。
「追及」→「追求」に直すべきところがスルーされてしまいました。惜しい。
【ケース3:知識としては知っているはず】
入力:マショマロを電子レンジで加熱するとふくらむ。
出力:マショマロを電子レンジで加熱するとふくらむ。
誤字が直ってないでショ?もしかしてLLMくん、マシュマロ知らない?
一般的な単語の誤字を見落とすケースもあることがわかりますね。
うーん、出力だけを見ているとあんまり直ってない感じはします。
では、数字での結果を見てみましょう!
| GPT-4o mini | 39.75% |
※3回実行した際の平均値
えっ……正解率、思ったより低い!
ちょっとショックです… 4oに切り替えて再検証してみましょう!
| GPT-4o | 51.38% |
※3回実行した際の平均値
若干の改善は見られましたが、まだ「半分ちょっと」レベルですね。
それでも、いらない修正を防ぐために「直さなくていい例」もプロンプトに入れたのが、少しは効いている…かも?とはいえ、プロンプト工夫だけでは限界も感じる結果
でした。
修正不要な文のチェック
気を取り直して、今度は逆に、「触っちゃダメな文」がちゃんとスルーされるかを見ていきます。
【ケース1: 完璧!】
入力:設備はエレベーター・エスカレーターが2006年に設置完了。
出力:設備はエレベーター・エスカレーターが2006年に設置完了。
全角数字も含め、そのまま!これは理想的。
【ケース2: 余計なお世話】
入力:そんな中、サスケは大蛇丸の部下である音の四人衆と接触、大蛇丸の元へと
誘い込む。
出力:そんな中、サスケは大蛇丸の部下である音の四人衆と接触し、大蛇丸の元へと
誘い込む。
「し」が勝手に追加されてしまいました。サスケがどうなってもいいんですか!?
【ケース3:意味は同じでも…】
入力:しかし信長はこの動きを良しとせず、1582年に盟約を反古にし、四国征伐
を決意する。
出力:しかし信長はこの動きを良しとせず、1582年に盟約を反故にし、四国征伐
を決意する。
意味は同じですが、漢字が書き換えられています。こういう細かい変化も「不必要な修正」として減点対象です。
この「修正不要な文」の正解率は……
| GPT-4o mini | 66.81% |
| GPT-4o | 75.78% |
※3回実行した際の平均値
こちらはやや高めでしたが、逆に言えば 約25~33%の文が余計に修正されてしまったということでもあります。惜しい!
詳細な評価結果
少し深掘りしてみましょう!GPT-4oによる1回の実行結果を詳しく見ていきます。
| LLMが修正した | LLMが修正しなかった | |
| 修正が必要な文 | 830件(うち579件は正しい修正) |
297件(見逃し)
|
| 修正が不要な文 | 273件(お節介) |
854件(正しく無視)
|
この表をもとに、いくつかの評価指標(あくまで参考)を算出しました。
-
修正が必要な文に対して、LLMが正しく修正できた割合:
51.38%(579/1127) - 修正が必要な文に対して、LLMが何らかの修正を行った割合(誤り検出の再現率/Recall):73.65%(830/1127)
-
LLMが修正を行った文のうち、修正が正しかった割合(参考値):
52.49%(579/1103) - LLMが修正を行った文のうち、修正が必要だった文の割合(誤り検出の適合率 / Precision)(参考値):75.34%(830/1103)
※この数値は、修正が必要なデータと、修正が必要でない同数のデータを組み合わせて評価
した結果です。そのため、誤字が少ない現実の文章にそのまま当てはまるとは限りません。 -
修正が不要な文に対して、LLMが修正を行わなかった割合:
75.78%(854/1127)
結果として、全体では約64%の文(579 + 854) / (1127 + 1127)を適切に処理できたことになります。一方で、修正すべき文のうち約26%(297/1127)を見逃し、修正が不要な文の
うち約24%(273/1127)に対して不必要な修正を行ってしまった点は、今後の改善の余地
があるといえます。
残された課題:
でも期待していた程直してはくれなかったですね…今回の検証で、LLMが特に苦手だと感じた具体的なポイントや、今後の改善が期待される点は以下の通りです。:
- 助詞の誤りへの対応が難しい
► 「が」「を」などの抜けや誤用に対して鈍感。
► 指示を丁寧に書いても、逆に誤修正を誘発するケースもありました。 - 表記揺れの対応が不安定
► たとえば「こと」⇔「事」など、意味は同じでも漢字/ひらがなの違いに対する修正
有無がバラバラ。
► ルールの曖昧さにLLMが引っ張られている印象です。 - 固有名詞や地名に弱い
► 例:函館(はこだて)大学の記事:LLMくん:函大(かんだい)?
大丈夫、誤字はないです! → 正解は「はこだい」。 - 修正の一貫性に欠ける
► 同じタイプの誤字でも、「直すとき」と「スルーするとき」が混在。
► 一貫性のなさが、品質管理上のネックになりそうです。 - 空出力になるケースが存在
► 特に性的・暴力的な文を含むと、出力が完全に空になることがありました。
► OpenAI側のコンテンツフィルターが影響している可能性。
► 正解率に影響を与えている。
結論と展望
今回の検証からわかったのは、プロンプト設計によってある程度の校正は可能ということ。AI初心者の私でも、試行錯誤を重ねることで、一定の成果を出せました。
一方で、今回の詳細な分析からは、以下のような課題も見えてきました。
- 修正精度の限界:
修正が必要な文のうち、LLMが適切に修正できたのは約51%にとどまりました。
また、誤りを含む文の約26%は見逃される結果となりました。
※ただし、これはデータセットの特性が影響している可能性があります。 -
「お節介」な修正:
修正が不要な文であっても、約24%がLLMによって余計に修正されてしまうケースが
ありました。 -
修正の一貫性の欠如:
同じ種類の誤り(例:助詞の抜け)に対しても、あるときは修正し、あるときはスルーするなど、対応が安定しませんでした。この一貫性のなさは、校正ツールとしての信頼性や品質管理上の課題となり得ます。LLMのtemperatureなどのパラメータを調整することで、出力の安定性を高められる方法も考えられます。 -
コンテンツフィルターによる空出力問題:
特に性的・暴力的な表現を含む文で、OpenAI側のフィルターが働き、出力が完全に空になることがありました。
今回は「文単位」での評価でしたが、もし段落や全文を入力して文脈情報を持たせたら、
また違った判断が変わった可能性もあります。今後の改善方針としては、文脈を与える工夫や表記ルールの明示、フィルター対策などが考えられそうです。
――とはいえ、日本語の校正って、やっぱり難しい!
正直、自分で校正しろって言われて、AIより上手く文章中の間違いを見つけられるかというと……怪しいですよね。某イタリアンファミリーレストランの間違い探しだって、けっこう難しいですし。
でも、だからこそ AIをどう活用するか、どう工夫するか に面白さがあると感じました。今回の経験を通じて、LLMの可能性と難しさを肌で感じることができました。
以上、誤字脱字編はここまでです!
次回【パート②】では、文章表現の校正編をお届けします!外来語の表記、数字の使い方、符号の使い方など、表記ルール校正に挑戦します。
【参考文献】







お問い合わせ・
導入のご相談
AI導入や活用についての
ご質問・ご相談はこちらから。
現状の課題やお悩みをもとに、
最適な進め方をご提案します。
資料ダウンロード
調和技研の事業や事例集をご覧いただけます。
AI活用の全体像を知りたい方におすすめです。