
Google のオープンLLM「Gemma」を試してみる|GPT-3.5 Turboとの比較あり


 参考: https://ai.google.dev/gemma?hl=ja[1]
参考: https://ai.google.dev/gemma?hl=ja[1]
Gemma の特徴
Gemmaの主な特徴として以下の三つが挙げられています。
• 設計における責任
これらのモデルには包括的な安全対策が組み込まれており、厳選されたデータセットと厳密なチューニングを通じて、責任ある信頼できる AI ソリューションを確保できます。
• 規模において比類のないパフォーマンス
Gemma モデルは、2B と 7B のサイズで優れたベンチマーク結果を達成し、一部の大規模なオープンモデルよりも優れています。
• フレームワーク フレキシブル
Keras 3.0 を使用すると、JAX、TensorFlow、PyTorch とシームレスに互換性があるため、タスクに応じてフレームワークを簡単に選択して切り替えられます。
Gemmaモデルは、複数のサイズが公開されており、モバイルデバイスやノートパソコン等のリソース要件の低い環境を想定した2Bモデルと、デスクトップコンピュータや小規模サーバ等を想定した7Bモデルがあります。特に Gemma 7B モデルは、代表的なオープンLLMである Meta社のLlama2、MistralAI社のMistralのモデルサイズと同様です。
|
Model |
Context-window |
Size |
|
google/gemma[2] |
8192 |
2B ~ 7B |
|
mistralai/Mistral[3] |
32768 |
7B, (8x7B, 8x22B MoE) |
|
Meta-llama/Llama2[4] |
4096 |
7B ~ 70B |
Gemma の性能
公式よりGemmaのベンチマークテスト結果が公開されており、Gemmaに近いパラメータ数をもつ既存のオープンLLMである Llama2、Mistralの結果との比較が行われています。結果として、質問応答、推論、数学、コーディングの4タスクにおいて同パラメータ数の既存モデルを上回るスコアが確認されています。また、Gemma 7Bよりもパラメータ数の大きいLlama 2 13Bと比較しても、匹敵もしくは上回る結果となっています。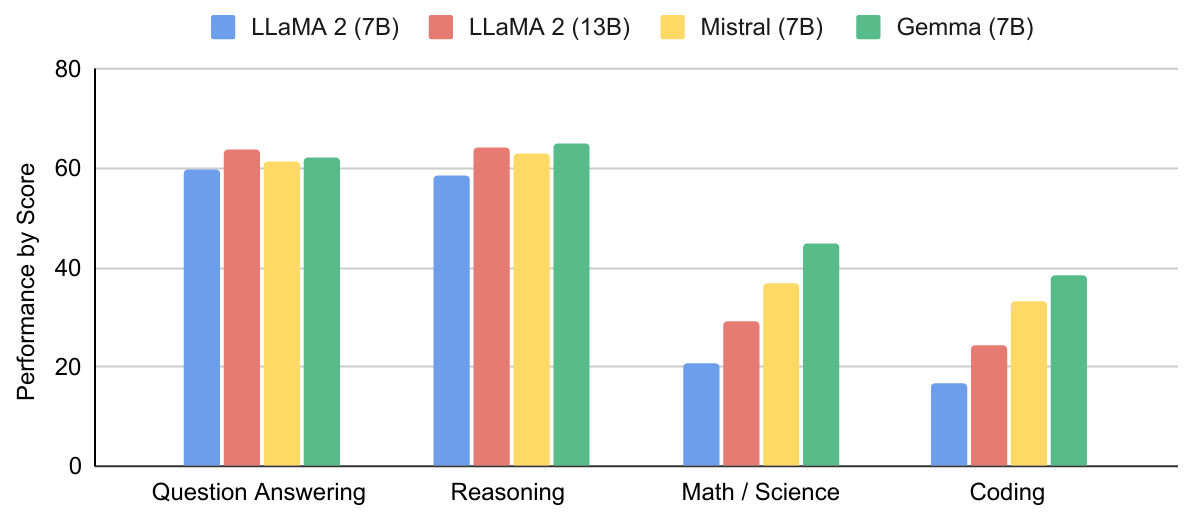
詳細はテクニカルレポート[5]をご確認ください。
Gemma の使い方
「Gemma」はHuggingFace上で公開されています。他のオープンソースモデルと同様にモデル名を指定することで利用できます。ただし、Gemmaは制限モデルであるため利用する際にはHuggingFace上でライセンスに同意して制限を解除する必要があります。
また、実行する際にもHuggingFaceアカウントと紐づける必要があるため、アクセストークンを取得しておきます。アクセストークンはログイン後のユーザアイコン>>Settings >> Access Tokensから取得できます。
実行
pip install transformers torchモデル名を“google/gemma-7b-it”と指定することで利用できます。また、モデルの読み込み時に先ほど取得したアクセストークンを指定します。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained(
"google/gemma-2b-it",
token = “YOUR_ACCESS_KEY”
)
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-2b-it",
torch_dtype=torch.bfloat16,
token = “YOUR_ACCESS_KEY”
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))詳細は、公式Documents[6]をご確認ください。
Gemma とOpenAI GPT-3.5 Turboを比較する
いくつかの質問への回答を Gemma と OpenAI 社の GPT-3.5 Turbo に質問し、どのような違いがあるか比較してみましょう。今回は公開されている Gemma モデルのうち instruction tuning が実施されている “google/gemma-2b-it”,“google/gemma-7b-it”を用います。
今回は、以下2つの問題にどのように回答するかを試してみました。
- 心のモデル
- 国語の問題
心のモデル
まずは、登場人物の心の状態を読み取ることができるかの問題を出題します。
以下のプロンプトを実行します。
|
①サリーとアンが部屋で一緒に遊んでいます。 ②サリーはボールをかごの中に入れて部屋を出て行きます。 ③サリーがいない間にアンがボールを別の箱の中に移します。 ④サリーが部屋に戻ってきます。 《問題》サリーはボールを取り出そうとして最初にどこを探しますか? |
それぞれのモデルの生成結果は以下のようになりました。
“Gemma 2B it”
|
①、②
サリーは部屋でボールを取り出す際に、まず部屋の入り口や部屋の他部分をよく確認します。 |
“Gemma 7B it”
|
①
これは、サリーがボールを取り出すために部屋内で最初の場所を確認するため、正解は①です。 |
“gpt-3.5-turbo”
|
サリーは最初にかごの中を探すでしょう。 |
|
Model |
Correct Answer Rate ( /10) |
|
gpt-3.5-turbo |
1.0 |
|
Gemma-2B-it |
0.0 |
|
Gemma-7B-it |
0.0 |
|
Correct-Answer |
– |
こちらの質問は、“かご”を探すが正答です。
GPT-3.5 Turboでは正答できていますが、Gemmaモデルはどちらも誤答になっており、①~④を過程ではなく回答の選択肢と認識しています。試行回数=10の場合の正答率は、Gemmaモデルはともに0.0になっており、すべて誤答になってしまいました。
国語の問題
次に、文章の内容から適切な回答を選択する国語の問題を試してみましょう。
以下のプロンプトを実行します。
|
次の文を読みなさい。 Alexは男性にも女性にも使われる名前で、女性の名Alexandraの愛称であるが、男性の名Alexanderの愛称でもある。 この文脈において、以下の文中の空欄にあてはまるもっとも適切なものを選択肢のうちから1つ選びなさい。 Alexandraの愛称は( )である。 ①Alex ②Alexander ③男性 ④女性 |
それぞれのモデルの生成結果は以下のようになりました。
“Gemma 2B it”
|
①Alex Alexは男性にも女性にも使われる名前で、女性の名Alexandraの愛称である。 |
“Gemma 7B it”
|
答案:①Alex |
“gpt-3.5-turbo”
|
①Alex |
|
Model |
Correct Answer Rate ( /10) |
|
gpt-3.5-turbo |
1.0 |
|
Gemma-2B-it |
0.5 |
|
Gemma-7B-it |
0.6 |
|
Correct-Answer |
– |
こちらの質問は、①(Alex)が正答です。
生成例ではどのモデルも正しく回答できています。試行回数=10の場合の正答率は、OpenAIのGPT-3.5 Turboの正答率1.0に対してGemma-2B-it=0.5, Gemma-7B-it=0.6と低い正答率となりましたが、低パラメータ数のモデルにもかかわらず半数以上は正答できていることがわかります。
Gemma のまとめ
本記事では、Google社が提供するLLMの「Gemma」についてご紹介しました。
今回は2つの質問を試してみましたが、GPT-3.5 Turboよりも劣っている結果となったものの「国語の問題」には50%程度の正答率で回答できています。対して、「心の問題」は全く正答できておらず、タスクによって得意不得意が大きく分かれた結果となりました。選択式の「国語の問題」への正答率が高い点や記述形式の質問である「心の問題」へ選択式で回答してしまっている点から、特に選択式での質問が得意であるのかもしれません。
Gemma 2B は、公開されているオープンLLMの中でも比較的モデルサイズが小さいものとなっていますが、今回の結果の中で Gemma 7B から大きく精度を落とすことはありませんでした。その点から、Gemmaは軽量モデルとして十分に活用できるかもしれません。
【参考文献】
[1]https://ai.google.dev/gemma?hl=ja
[2]https://www.kaggle.com/models/google/gemma
[3]https://mistral.ai/technology/#models
[4]https://llama.meta.com/llama2/







お問い合わせ・
導入のご相談
AI導入や活用についての
ご質問・ご相談はこちらから。
現状の課題やお悩みをもとに、
最適な進め方をご提案します。
資料ダウンロード
調和技研の事業や事例集をご覧いただけます。
AI活用の全体像を知りたい方におすすめです。