
大規模言語モデルによるソースコード生成:GitHub CopilotからCopilot Xへの進化と未来


こんにちは。調和技研 研究開発部の高松です。この記事では、大規模言語モデル(LLM)によるソースコード生成の能力とその進化について説明します。特に、GitHub Copilotの機能とその進化形であるGitHub Copilot Xを説明し、その効果、制限事項、及び今後の展望について考察します。
LLMとそのソースコード生成の能力
ChatGPTをはじめとするLLMの利用は非常に広範囲に渡りますが、その活用事例の一つとしてソフトウェア開発における利用があります。この記事では、まずはソースコード生成にどのように活用されているのかについて解説します。特に、GPTモデルがどのようにソースコードを学習し、それを生成する能力を持つのかについて説明します。
現在、登場している多くのLLMの学習データ(コーパス)にはプログラムのソースコードが含まれていることが多いです。ChatGPTの前身のモデルであり、GitHub Copilotに使われているOpenAI社のCodeXと呼ばれるモデルは、GPT-3をベースにGitHubのpublicリポジトリで学習したものです。大量のデータで学習しており、Pythonコードだけで、GitHubの5400万件のリポジトリから159GBのデータを学習に使っている[1]と報告されています。10以上の言語を扱えますが、特に、「Python」「JavaScript」「TypeScript」「Ruby」「Go」「C#」「C++」あたりが得意な言語と言えるようです。
自然言語よりもソフトウェアプログラムの方が構造が規則的であるため、LLMはソースコードの生成を簡単に扱うことができます。
GitHub Copilot
GitHub Copilotは最も先行しているソフトウェア生成支援サービスの1つで、前述のCodeXのモデルをベースとしてコード補完を行います。Visual Studio Code、Visual Studio、Neovim、JetBrainsなどのIDEから利用可能です。コード生成そのものはChatGPTなどでもできるわけですが、コードを書くツールに連携することで飛躍的に利用しやすくなります。
GitHub Copilotの基本的な使い方
GitHub Copilotの使い方を具体的な生成例を用いて説明します。
一般的な利用の形態は、関数の説明やシグネチャなどソースコードの途中までを入力した状態で、その続きを生成させる形になります。以下は、関数の説明とシグネチャを入力すると、その実装をCopilotが生成して提案した例です。利用者はその提案を受け入れたり、別な提案をさせるといった操作ができます。
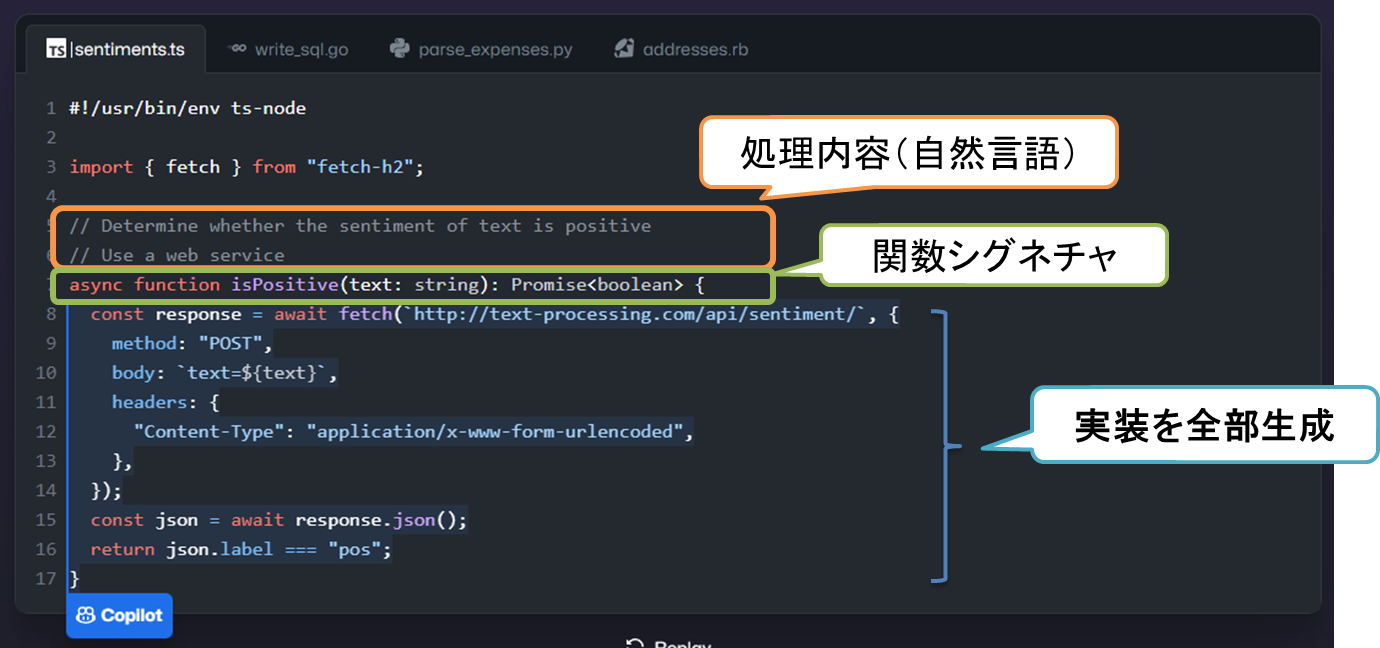
※以降もオフィシャルサイトの例 https://github.com/features/copilot です。
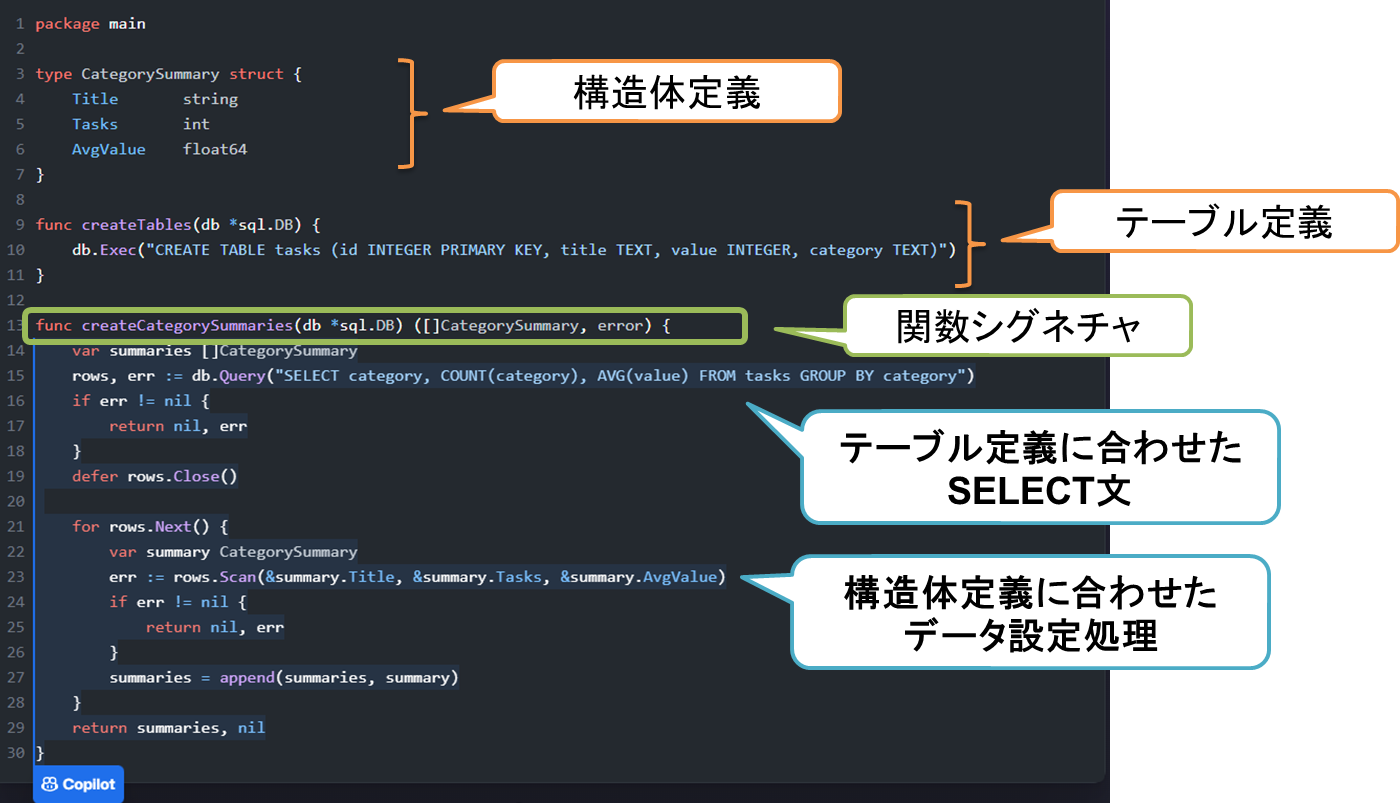
複数の言語を学習しているため、こちらで決めた構造体定義とテーブル定義を参考にSELECT文を生成し、構造体に値を詰めるといったコードも生成することができます。
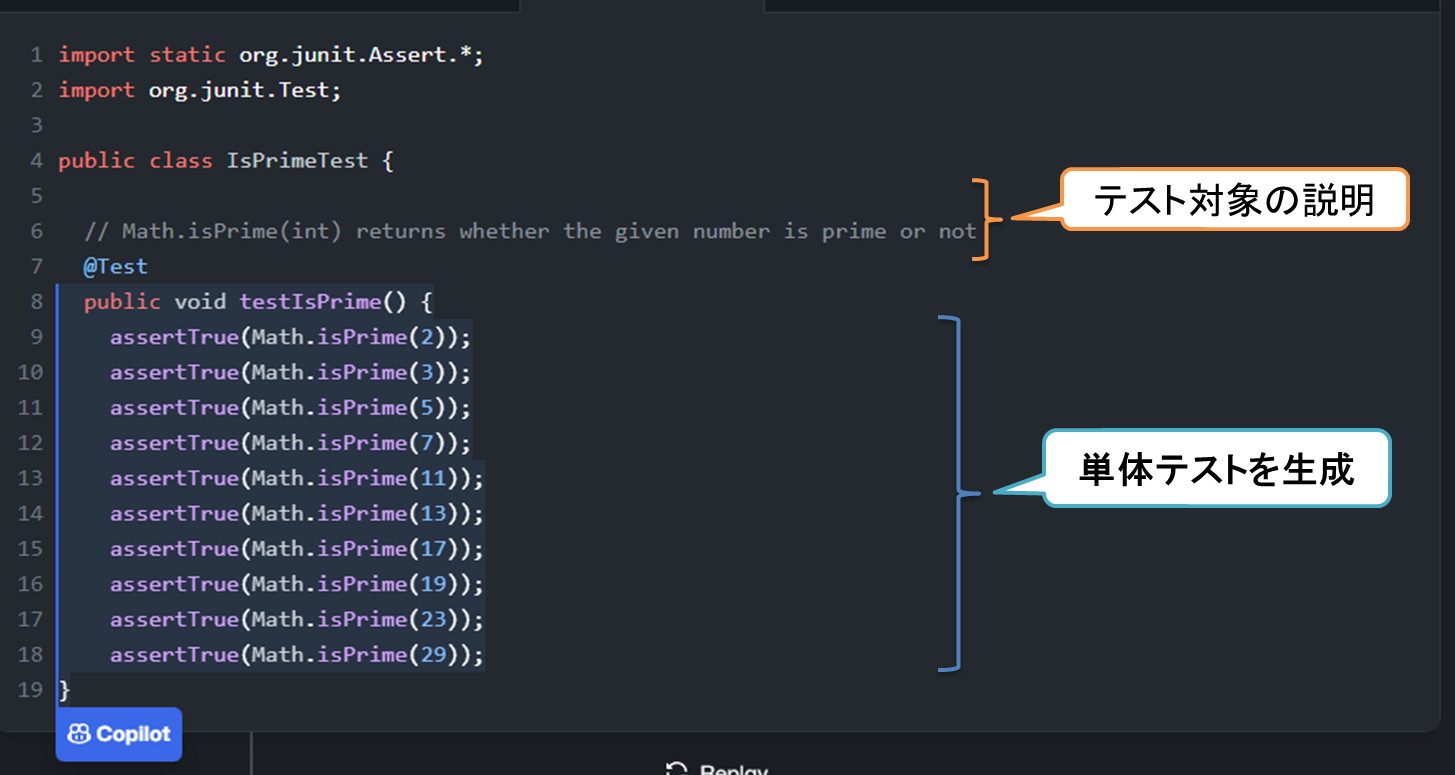
こちらは、テストコードを生成する例です。テスト対象の説明をコメントしたうえでテストコード(JUnit)のシグネチャを書いて生成させています。
このほか、テキストのパース処理なども厳密な定義なしに例示ベースの説明で実装するなどよくある処理は概ね対応できる感触です。
GitHub Copilotの効果と制限
GitHub Copilotの効果と制限を詳細に説明します。生産性については、厳密な効果測定がなかなか難しい部分ではありますが、GitHub自身が提供しているレポートでは、提案したコードの26%が採用され、全体で50%の生産性向上に寄与していると報告しています[2]。特に利用者の満足度は高く、当社でも利用したメンバーは、これなしでコードを書きたくないと考えるメンバーが増えています。
制限としては、正しいコードを出力する保証はなく、コンパイルが通るか、動作が正しいかを利用者側で確認する必要があります。また、LLMの常として、一度に見られる範囲(コンテキスト)は限られています。このため、例えば、自作のライブラリを利用するようなコードを書く場合、そのライブラリのヘッダだけを開いておくなど、LLMが参照する範囲をある程度ユーザ側で調整する必要があります。
GitHub Copilot X
Copilot Xは2023年3月に発表された次世代のコード生成のビジョンですが、その一部であるCopilot Chatは既に利用できるようになっています。ポイントは、モデルがGPT-4ベースとなってより高性能になったこと、及び、対話形式のインタフェースを取ることで、より利用の敷居が下がったことが挙げられます。つまり、他の人間に頼むような感覚でCopilotに指示を出すことができます。
以下は、単体テストを生成させる例です。
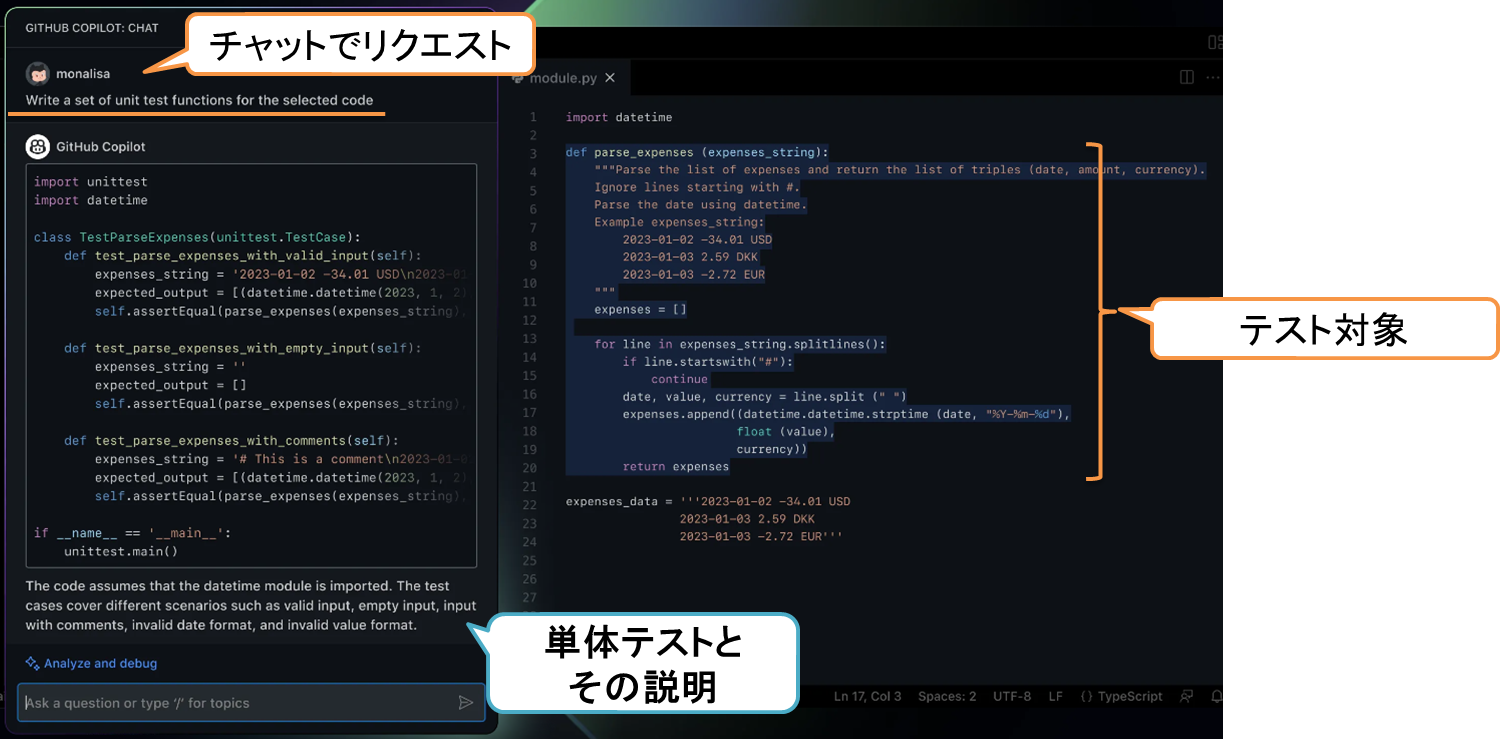
テスト対象を選択したうえで、「選択したコードの単体テストを書いて」と指示するだけです。前述した補完の手法に比べて、より直感的な利用ができるようになったと思います。
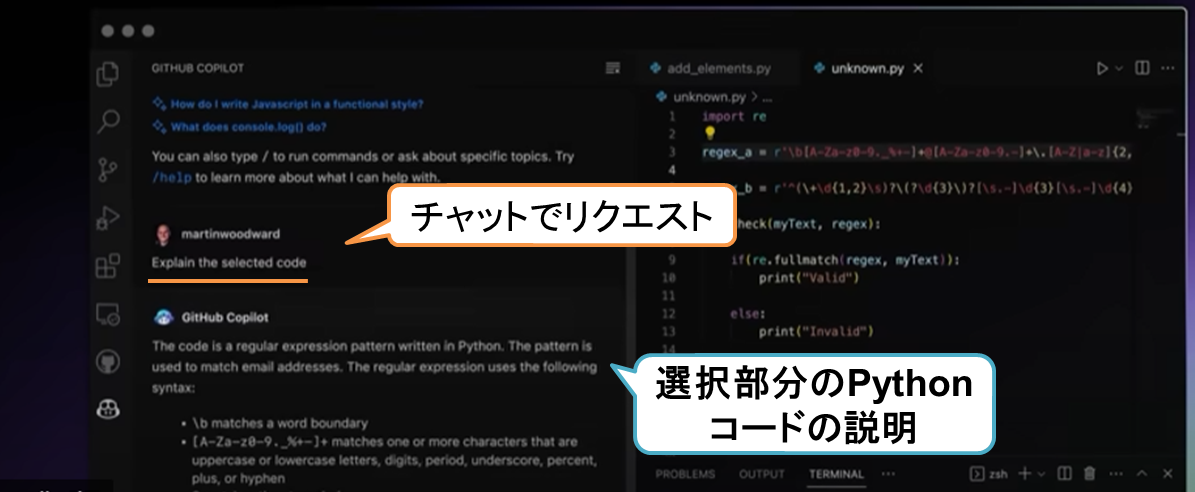
また、GPT-4ベースとなってコード生成の能力自体が底上げされたほか、自然言語での説明力も上がっています。以下は、コードの内容を説明される例です。対話形式になって会話のインタラクションもできるので、未知のコードを読み解いたり、デバッグを一緒に行うといった活用が見込めます。
競技プログラミング
LLMが持つコード生成能力はどれくらいなのでしょう。GPT-4が登場した際のレポートでは、競技プログラミングでの成績は下位5%[3]という数字でした。GPT-4の受け答えを知っているとかなり低く感じるのではないでしょうか。ただ、実際には人間がアシストするとかなり成績もあがります。先日、Google (DeepMind)がGeminiを発表しましたが、合わせてAlphaCode2も発表されました。Gemini Proをベースとしてチューニングを行い、競技プログラミングで上位15%の成績が出せるようになってきます[4]。
今後の展望
1つの潮流は、学習データのライセンス関係をクリーンにしたコーディング特化のLLMも性能向上が進んでおり、ChatGPT-3.5相当のモデルが出てきています。これらはモデルパラメータ規模が相対的に小さくローカル実行が可能なため、完全にクローズドな動作環境を求める状況でも利用が可能になってくるでしょう。もう1つの方向性は、ソフトウェア開発のより幅広い範囲をサポートすることです。実行環境と合わせてデバッグしたり、ChatDev[5]などは仮想のソフトウェア会社としてプログラマ、テスターなど複数のロールのAgentがチャットしながら開発をするといった内容が研究されています。
大規模言語モデルによるソースコード生成は、ソフトウェア開発の効率化に大きな可能性を秘めています。調和技研でも、希望者にはGitHub Copilotを導入していますが、一度利用するとAIアシストなしでの開発が考えられないという状況になってきています。
【参考文献】
[1]Evaluating Large Language Models Trained on Code, https://arxiv.org/pdf/2107.03374.pdf
[2]Productivity assessment of neural code completion | Proceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming
[3][2303.08774] GPT-4 Technical Report ( arXiv.org e-Print archive)
[4] AlphaCode2_Tech_Report.pdf (storage.googleapis.com)
[5] [2307.07924] Communicative Agents for Software Development (arxiv.org)







お問い合わせ・
導入のご相談
AI導入や活用についての
ご質問・ご相談はこちらから。
現状の課題やお悩みをもとに、
最適な進め方をご提案します。
資料ダウンロード
調和技研の事業や事例集をご覧いただけます。
AI活用の全体像を知りたい方におすすめです。