
【GroqCloud】 爆速回答!?GroqCloudの実力とは


Groq社の概要
▍会社概要
Groq社は2016年にカリフォルニア州で設立され、独自の機械学習専用のハードウェアを
開発するテクノロジー企業です。CEOのJonathan Ross氏は、GoogleのTensor Processing Unit (TPU)の開発に携わっており、昨今のAIチップなどのハードウェアを牽引する開発者の一人でもあります。
Groq社が提供するGroqCloudの最大の強みは、独自開発したLanguage Processing Unit(LPU)を手軽に使用できる点にあり、このLPUは従来のGPUより圧倒的な推論速度と効率性を実現できると言われています。
GroqCloudでは、APIを通じてこのLPUを使用でき、ユーザが容易に高速な推論を実現できる環境となっています。
▍最近の動向
|
年表
|
動向
|
| 2016年 | Groq社 設立 |
| 2024年3月 | GroqCloud サービス開始 (リリースからわずか7週間で10万人以上のユーザが利用開始) |
| 2024年3月 | Definitive Intelligenceを買収(GroqCloudの機能を強化が目的) |
| 2024年8月 | 6億4000万ドル(約946億円)を調達 |
GroqCloudの利用例
▍ブラウザ上でプロンプト実行
「PlayGround」へアクセスして実行できます。
※事前にメールアドレスの登録が必要です。(g-mailなどで登録可能)
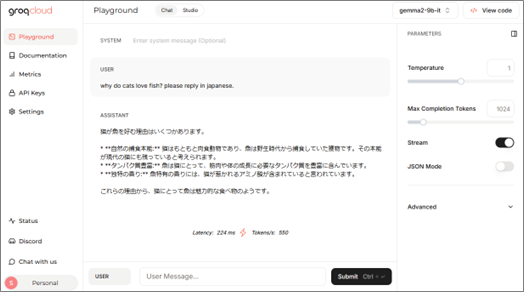
【図2】 PlayGround(*1)
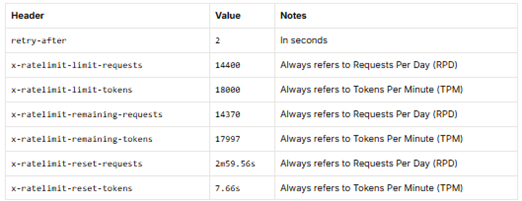
▍制限
2025年1月24日時点で、下記のような制限となっています。
リクエストは1日14.4k、トークン数は1日に18kでGPTなどと、比較すると少量のため、
チャットボットなどへのサービスに導入を考えている場合は注意が必要です。
▍使用量の監視
「Metrics」より実行ステータスや使用したトークンの総量などが確認でき、モデルやAPI Keyごとに見ることもできます。
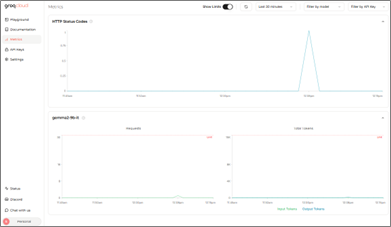
【図3】 Metrics(*1)
▍API Key
「API Keys」よりAPI Keyを作成可能です。呼び出し回数の制限は自分で設定できず、
24時間で720回までと決まっているようです。
サービスに組み込む場合は、トークン制限などと合わせてこちらも注意が必要です。
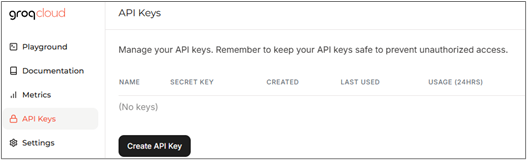
【図4】 API Keys(*1)
Pythonでの実行例
GroqCloudのPlaygroundで得られるサンプルをベースに、簡単な命令を実行しました。
▍環境例
- Python 3.12
- groq (python用Groqライブラリ)

▍コード実装例
▍実行結果
| 猫が魚を愛する理由は、いくつか考えられます。
* **進化の痕跡:** 猫はもともと肉食動物として進化し、野生では小魚を捕食していました。そのため、魚のような脂っこくタンパク質豊富な食物を本能的に好む習性を持っているのかもしれません。 * **アミノ酸と香り:** 魚には、猫が特に好むタウリンやアラニンなどのアミノ酸が含まれており、食欲をそそります。また、魚独特の香りが猫を引きつけるとも言われています。 * **嗜好性の個人差:** すべての猫が魚を喜ぶわけではなく、個体差はあります。人間と同じように、猫にも特定の味が好き嫌いが存在します。 これらの要素が組み合わさって、猫が魚を好み、美味しいと感じるのかもしれませんね。 |
▍100回実行した場合の応答速度
大体1回の実行において、0.3秒前後で回答されました。
トークン数やモデルで変わるため、一概に比較はできませんが、ローカルモデル(Qwen2.5-3B-Instruct)の実行が、今回実験した環境では20秒以上なことを考えると、たしかに「爆速」という評価は正しそうです。
この速度が出せるサーバー代を考えると、無料で使用できる (2025/1/24現在) GroqCloudは、個人研究者や開発者にとって強い味方となりそうです。
ちなみに、ローカルモデルを実行した環境でgpt-4o-miniの応答速度は0.1秒前後だったため、APIとして考えると単純な応答速度ではまだGPTに軍配が上がっています。
ただし、「GroqCloudでLlama3 8Bモデルを使用した際、1秒で800トークン出力できる」
という情報もあるため、今回のような小さいサイズのモデルの単純な処理ではなく、大きなモデルやトークン数が多くなったとき、GroqCloudの本領が発揮されてきそうです。
| モデル名 | 応答速度の算術平均 [sec.] | 標準偏差 |
| GroqCloud)gemma2-9b-it | 0.26 | 0.04 |
| GroqCloud)llama-3.2-1b-preview | 0.25 | 0.04 |
| Qwen2.5-3B-Instruct | 23.6 | 11.19 |
| gpt-4o-mini | 0.09 | 0.02 |
参考
- Groq is Fast AI Inference
<ニュース / テックニュース>—————————————————————-







お問い合わせ・
導入のご相談
AI導入や活用についての
ご質問・ご相談はこちらから。
現状の課題やお悩みをもとに、
最適な進め方をご提案します。
資料ダウンロード
調和技研の事業や事例集をご覧いただけます。
AI活用の全体像を知りたい方におすすめです。