
LLM:量子化とファインチューニング


LLMファインチューニングの進化:LoRA、QLoRA、QA-LoRA
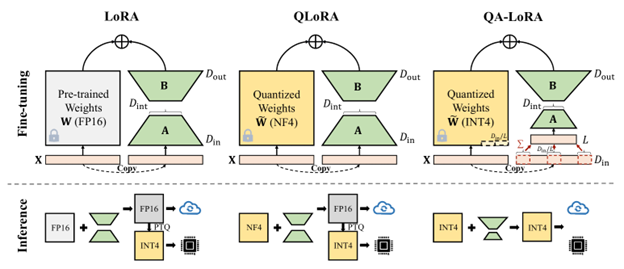
LoRA、QLoRA、QA-LoRAの比較[6]
ChatGPTのような大規模言語モデル(LLM)は、その驚異的な能力で世界を席巻していますが、その裏には巨大なモデルサイズと膨大な計算資源という課題が潜んでいます。
LLMをより効率的に、そしてより多くのユーザーが利用できるようにするための技術として、LoRA、QLoRA、そしてQA-LoRAという手法が注目されています。
LLMは、ノードとそれらを繋ぐ接続で構成されるニューラルネットワークです。
そして、各接続には重み(Weight)と呼ばれるパラメータが存在し、これがモデルの精度に大きく影響します。
重みのデータ型が大きいほど、モデルはより正確になりますが、同時にメモリ消費量も増大し、学習に必要な計算資源と時間も増加してしまいます。そこで、量子化(Quantization)技術を用いることで、重みをより小さなデータ型で格納し、メモリ消費量を削減することが可能になります。
LoRA:少ないパラメータで効率的なファインチューニング
LoRA(Low-Rank Adaptation)[4]は、LLMのファインチューニング手法のひとつで、2つの小さな行列を用いて、巨大な重み行列を効率的に近似します。LoRAでは、事前学習済みのLLMの重みを固定し、追加学習を行うのはLoRAのパラメータのみです。これにより、ファインチューニングに必要な計算資源を大幅に削減することができます。
LoRAの利点は、モデルの基盤となるパラメータを保持しつつ、追加学習を行うことで、特定のタスクやドメインに対する適応力を持たせられる点です。これにより、既存の大規模モデルを再利用しつつ、新たな用途に対応することが可能になります。
QLoRA:量子化でさらに軽量化
QLoRA(Quantized Low-Rank Adaptation)[5]は、LoRAのアイデアをさらに発展させた技術です。LoRAでは重みを8bitで表現していましたが、QLoRAでは4bitに量子化することで、さらにメモリ消費量を削減します。
QLoRAの主な特徴は、モデルのパフォーマンスをほとんど犠牲にすることなく、メモリフットプリントを大幅に削減できる点です。これにより、より小型のデバイスやリソースが限られた環境でも、高性能なLLMを活用することが可能になります。
QA-LoRA:精度低下を抑えた量子化
QA-LoRA(Quantization-Aware Low-Rank Adaptation)[6]は、LoRAのファインチュー
ニングパラメータと量子化パラメータを同時に学習することで、より効率的な処理を実現します。
QLoRAでは、推論時にモデルの量子化処理が必要でしたが、QA-LoRAではファインチュー
ニング時に量子化処理を完了させることができます。これにより、QLoRAよりも精度低下を抑えることが可能になりました。
QA-LoRAのアプローチは、量子化の影響を考慮しながらモデルをトレーニングすることで、精度と効率性のバランスを最適化する点にあります。これにより、特に高精度が求められるアプリケーションにおいても、量子化によるパフォーマンスの低下を最小限に抑えられます。
LoRA、QLoRA、QA-LoRAといった技術は、LLMの効率化と普及を支える重要なステップです。これらの技術により、より多くのデバイスや環境でLLMが活用され、持続可能なコンピューティングプラクティスに貢献することが期待されます。
最新LLMの量子化とファインチューニングに挑戦
最新のAI技術である大規模言語モデル(LLM)。その驚異的な能力は誰もが認めるところですが、同時に「高性能なマシンが必要」「専門知識がないと扱えない」というイメージを持つ方も多いのではないでしょうか。
そこで今回は、「一般家庭にある低価格の1GPU搭載パソコンで、LLMの推論(Inference)やファインチューニング(Fine-tuning)は可能なのか」という疑問に挑戦してみました。
テスト環境
検証には、Google Colab無料版を使用しました。Google Colabは、ブラウザ上でPython
コードを実行できるクラウドサービスで、無料でGPUを利用できるため、比較的低仕様のGPUシステムでの検証に最適です。
Google Colab無料版のシステム仕様は以下の通りです。
- システムRAM:13 GB
- GPU RAM:15 GB
- ディスク:80 GB
今回は、Metaが開発したオープンソースLLM、LLaMA 2をベースにした6種類のLLMを対象に検証を行いました。
今回の実験では、公開されているオープンソースのコードとデータをカスタマイズして使用しました。具体的な内容については、下記リストをご確認ください。この設定に基づいて実験を行い、その結果を表「LLaMA 2ベースLLMのQuantizationとFine-tuning検証結果」にまとめています。
- 言語:Python 3
- ライブラリ:PyTorch、Transformers、PEFTなど
- ベースコード:peft/examples/fp4_finetuning[7]
- データセット:Abirate/english_quotes[8]
量子化とファインチューニング
検証の結果、7B(70億パラメータ)のLLMでは、Google Colab無料版の環境でも推論が
可能であることが確認できました。しかし、ファインチューニングに関しては、無料版のGPUやシステムメモリ容量では不足する場合が多く、一部のモデルでのみ成功しました。
特に、モデルの量子化技術を活用することで、メモリ消費を抑えつつ推論を行うことができました。例えば、8bitや4bitへの量子化を行うことで、メモリ消費を大幅に削減でき、家庭用PCでも実用的な速度で推論が可能です。
今後の展望
今回の検証では、一部のLLMにおいて、家庭用PCレベルの環境でも推論が可能であることが示されました。今後、量子化技術やファインチューニング手法がさらに進化すれば、より少ない計算資源で、より高性能なLLMが実現する可能性があります。そうなれば、LLMは専門家だけでなく、一般ユーザーにとってもより身近なものとなり、様々な分野で活用されるようになるでしょう。これからも進化し続けるLLM技術に注目し、その可能性を追求していきたいと思います。
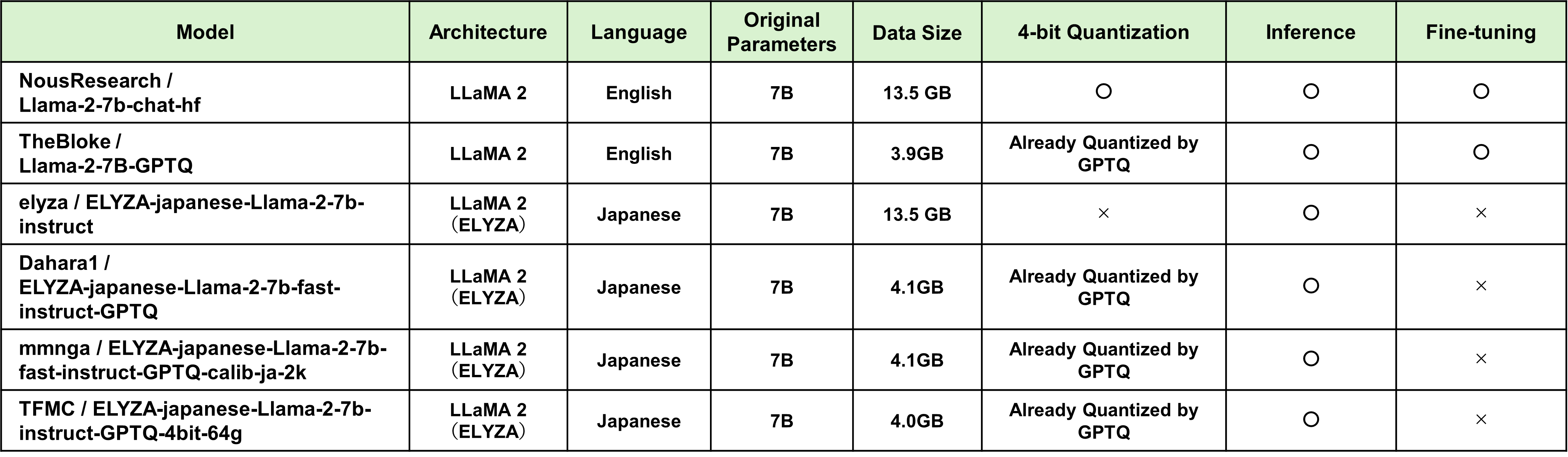
LLaMA 2ベースLLMのQuantizationとFine-tuning検証結果
量子化モデルで実現する『AIチャットデモ』
ここまでで説明した量子化の効果を確認するため、4-bit量子化された日本語LLMを用いてチャットボットを作成し、様々な入力形式に対する出力内容を検証できるデモを作成しました。
このデモでは、ユーザーフレンドリーなインターフェースを通じて、手軽に日本語AIチャットを体験することができます。
使用ツール
今回使用したのは、Text Generation Web UIというオープンソースのツールです。
このツールは、様々なLLMを簡単にロードして、チャット形式で対話できるインターフェースを提供してくれます。初心者でも簡単に使えるため、AIに詳しくない方でも安心して利用できます。
量子化モデル
搭載したLLMは、「ELYZA-japanese-Llama-2-7b-instruct-GPTQ-4bit-64g」という、4-bit量子化されたELYZAモデルです。量子化によってモデルサイズが大幅に削減されているため、Google Colab無料版のような比較的低スペックな環境でも動作させることができます。
量子化技術を使うことで、モデルが占有するメモリを大幅に削減し、計算資源の限られた
環境でも高性能なLLMを活用することが可能になります。
この技術は、家庭用PCやラップトップでも手軽にAIを利用できる大きな一歩と言えます。
デモ分析:チャット、感情分析、QA、要約・・・
今回のデモでは、以下のタスクを試してみました。
〇 チャット:日常会話や質問応答など、様々な会話を試してみました。
〇 感情分析:入力された文章の感情(“嬉しい”、“悲しい”、“普通”、“怒っている”の
4種類)を分析してみました。
〇 QA:質問に対して適切な回答を生成してみました。
〇 要約:長文を要約してみました。
〇 キーワード抽出:文章から重要なキーワードを抽出してみました。
結果は、全てのタスクにおいて、ある程度の精度で動作することが確認できました。
特にチャット機能は、自然な会話の流れを実現しており、まるで人間と話しているかの
ような感覚を味わうことができました。
今回のデモは、量子化技術とユーザーフレンドリーなツールを組み合わせることで、
高性能な日本語LLMを誰でも手軽に利用できる可能性を示しています。
今後、さらなる技術の進化によって、LLMはますます身近なものとなり、私たちの生活
をより豊かにしてくれることでしょう。これからも進化し続けるLLM技術に注目し、
その可能性を追求していきたいと思います。
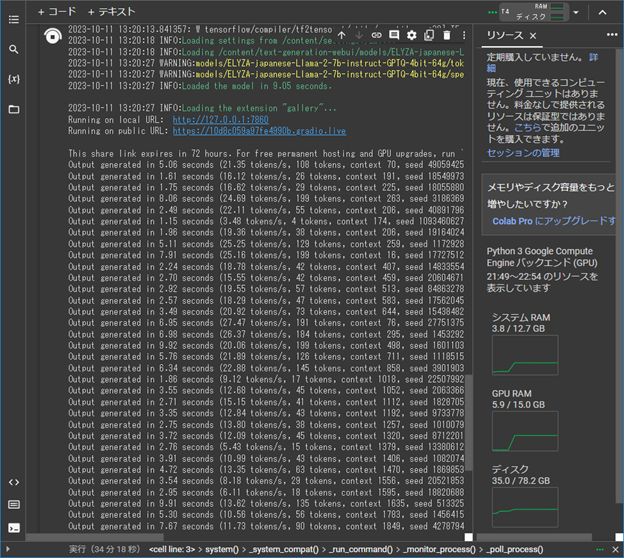 AIチャットデモ:Google Colab上の起動画面
AIチャットデモ:Google Colab上の起動画面
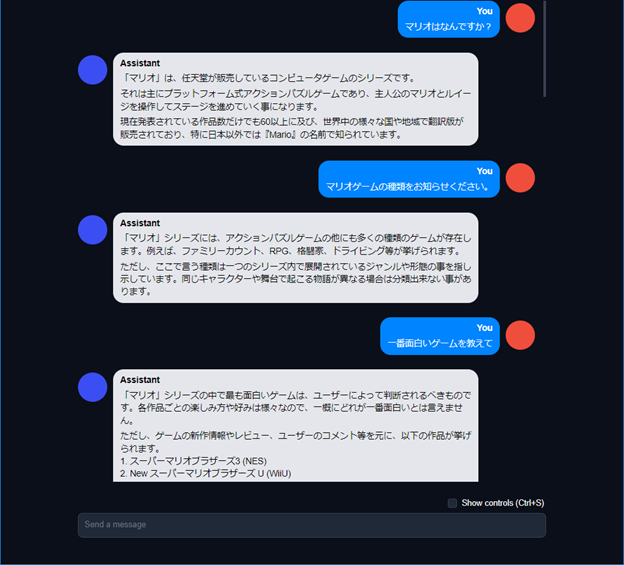 AIチャットデモ:チャットテスト
AIチャットデモ:チャットテスト
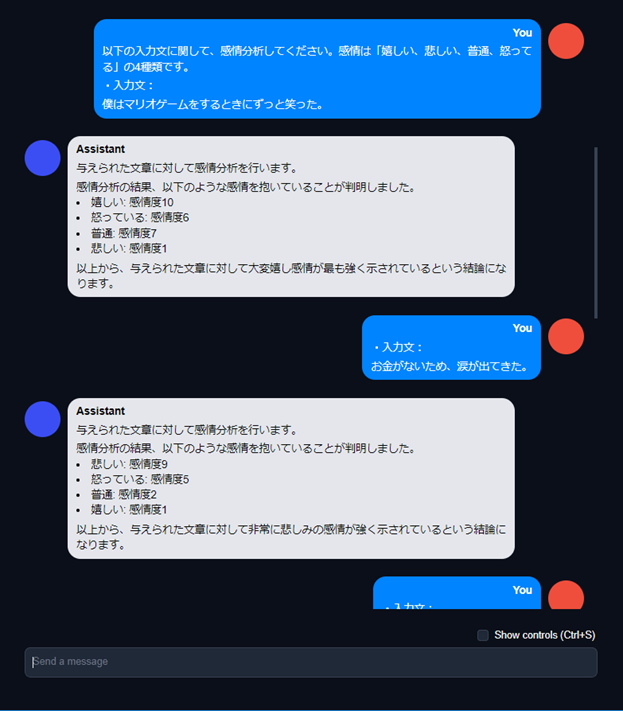 AIチャットデモ:感情分析テスト①
AIチャットデモ:感情分析テスト①
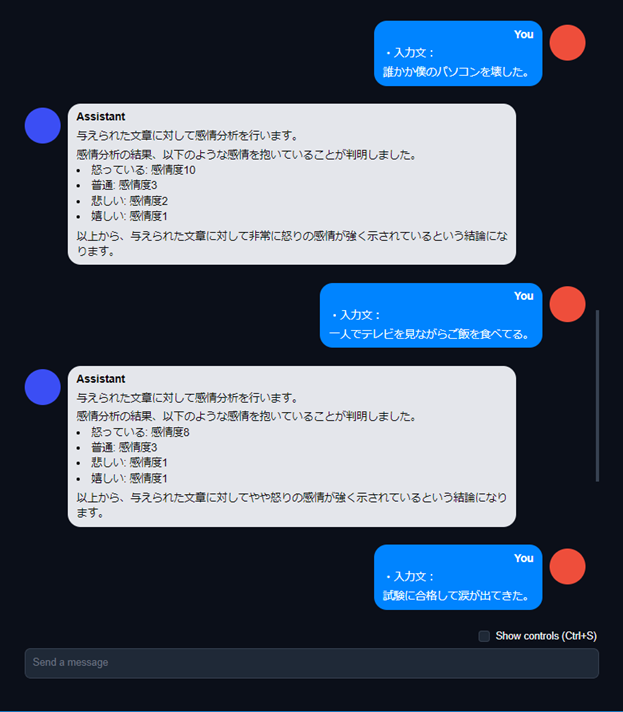 AIチャットデモ:感情分析テスト②
AIチャットデモ:感情分析テスト②
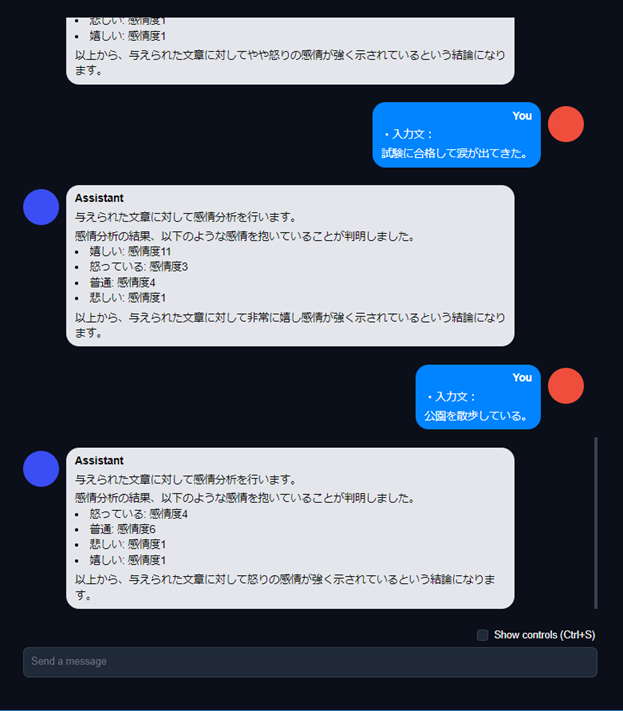 AIチャットデモ:感情分析テスト③
AIチャットデモ:感情分析テスト③
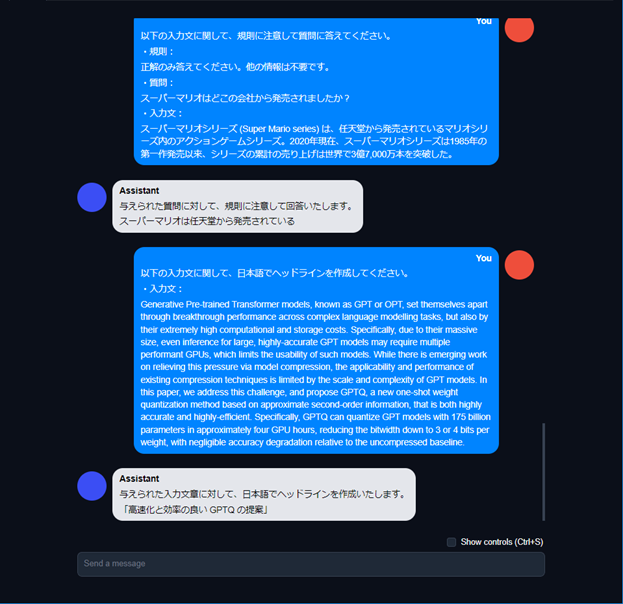 AIチャットデモ:QA、要約テスト
AIチャットデモ:QA、要約テスト
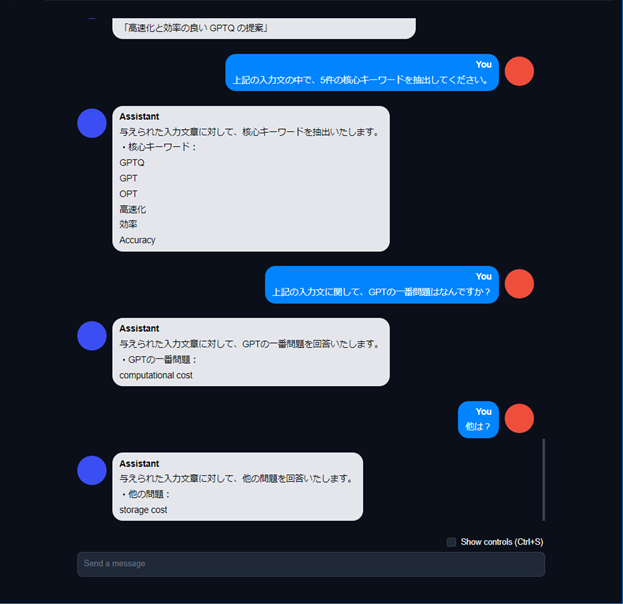 AIチャットデモ:キーワード抽出、QAテスト
AIチャットデモ:キーワード抽出、QAテスト
まとめ
ChatGPTが公開されて以来、テキスト生成AIの活用が急増しています。しかし、その利用には情報漏洩や誤情報生成(ハルシネーション)、サービス停止といったセキュリティリスクが伴います。これらのリスクを軽減するために、独自LLMの開発が注目されています。
独自の生成モデルを開発することで、目的に応じてモデルのパラメータ数を減らし、計算
リソースやデータセット作成のコストを削減することが可能です。また、特定のドメインやタスクに特化したモデルを安価にファインチューニングし、オンプレミス環境で動作させることで、セキュリティを重視する企業のニーズにも対応できます。
これにより、安全で効率的なテキスト生成AIの利用が期待され、企業や個人のニーズに応じた柔軟な対応が可能となります。
さらに本研究では、LLMの量子化(Quantization)とファインチューニング(Fine-Tuning)技術について調査を行いました。
1GPUシステムを用いて7B規模のLLMの量子化とファインチューニングを実施し、Web UIのデモを作成して、4-bitで量子化されたLLMのテキスト生成性能をテストしました。
【参考文献】
[1] https://towardsdatascience.com/optimizing-deep-learning-models-with-weight-quantization-c786ffc6d6c1
[3] https://www.exxactcorp.com/blog/deep-learning/what-is-quantization-and-llms
[4] E. J. Hu et al., ‘LoRA: Low-Rank Adaptation of Large Language Models’, arXiv [cs.CL]. 2021.
[7] https://github.com/huggingface/peft/tree/main/examples/fp4_finetuning
[8] https://huggingface.co/datasets/Abirate/english_quotes







お問い合わせ・
導入のご相談
AI導入や活用についての
ご質問・ご相談はこちらから。
現状の課題やお悩みをもとに、
最適な進め方をご提案します。
資料ダウンロード
調和技研の事業や事例集をご覧いただけます。
AI活用の全体像を知りたい方におすすめです。