
【MoA】 ローカルモデルを組み合わせてgpt-4o-miniと同等の性能?「Mixture of Agents」を試してみる


MoAの概要
MoAは、複数の大規模言語モデル(LLM)を組み合わせて、各モデルの強みを活かし、モデルのサイズやデータの偏りなどの弱点を補完する手法です。
MoAは複数の層に分かれており、それぞれの層に複数のLLMが配置される階層型アーキテクチャです。各レイヤーには複数のLLMが配置され、各LLMは前層の出力を補助情報に利用し、より良い応答を生成します。MoAでは、異なるLLMが前層の出力を利用しつつ、段階的に情報を精緻化していくことで、モデルサイズが小さいLLMがGPTのような大規模なLLMを超える性能を発揮できる可能性があります。
ただし、処理が複雑になり、単体のLLMを実行するよりも時間がかかるというデメリットがあります。
▍論文記載の評価結果の概要
MoAの提案論文では、3種類のMoA構造について評価を実施。
| MoA-Lite | コスト優先のMoA(Layer数が全2層) |
| MoA | 論文デフォルトのMoA(Layer数が全4層) |
| MoA w/GPT-4o | 論文デフォルトのMoA(Layer数が全4層)且つ 高品質な出力を優先 |
▍使用モデル
◎Proposer(*2)として使用
| ●Qwen1.5-72B-Chat |
| ●WizardLM-8x22B(Xu et al., 2023a) |
| ●LLaMA-3-70B-Instruct(Touvron et al., 2023b) |
| ●Mixtral-8x22B-v0.1(Jiang et al., 2024) |
| ●dbrx-instruct(The Mosaic Research Team, 2024) |
◎Aggregator(*3)として使用
| ●MoA-LiteのAggregator | Qwen1.5-110B-Chat(Bai et al., 2023) |
| ●MoAのAggregator | Qwen1.5-72B-Chat |
| ●MoA w/GPT-4oのAggregator | GPT-4o |
*2 Proposerは図1のLayer 1 ~ 3に記載の“A1~3, 1~3”にあたるLLM
*3 Aggregatorは図1のLayer 4に記載の“A4, 1”にあたるLLM
▍各評価指標における検証結果
本項では、論文記載のAlpacaEval 2.0, MT-Bench, FLASKの3種類のスコアの概要を
記載します。
◎AlpacaEval 2.0
AlpacaEvalはユーザーの指示に従う能力をテストする評価です。
検証ではMoAがトップ性能を達成し、特にGPT-4oをAggregatorとして使用した
MoAw/ GPT-4oは、以前のトップであったGPT-4 Omniより 8.2point も精度が
向上しました。
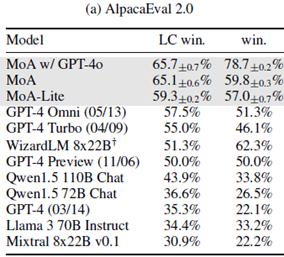
【図2】MoA-AlpacaEvalの評価結果 (*1)
◎MT-Bench
LLMがマルチターンダイアログ(複数のやり取りを通じて行われる会話)の流れと指示に
従う能力の評価です。MT-Bench においてもMoAによる性能向上が確認できました。
8 point以上も精度改善したAlpacaEvalと比較し、MT-Benchでは、スコア改善度合いが
少なくなっています。
これは、MT-Benchが10点が満点となっており、既存の結果の時点で9点以上を獲得して
いるため、スコアの改善度合いが少ないように見えています。
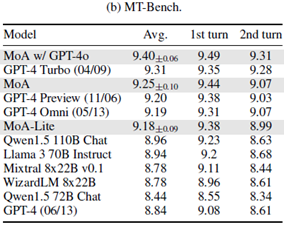
【図3】MoA-MT-Benchの評価結果 (*1)
◎FLASK
FLASKは、質問に対してLLMの回答が基準を満たしているか評価します。評価は5段階で、
正確性などの合計12個のカテゴリについて評価します。MoAとAggregator として使用した
LLM(Qwen-110B-Chat)単体のスコアを比較すると「堅牢性、正確性、効率性、事実性、
常識性、洞察力、完全性」の精度が改善しました。
GPT-4 Omniのスコアと比較すると、MoAは「正確性、事実性、洞察力、完全性、メタ認
知」で上回りました。ただし、MoAは「簡潔さ」のスコアが低く、LLM単体より冗長な
出力を生成する傾向があることが分かります。
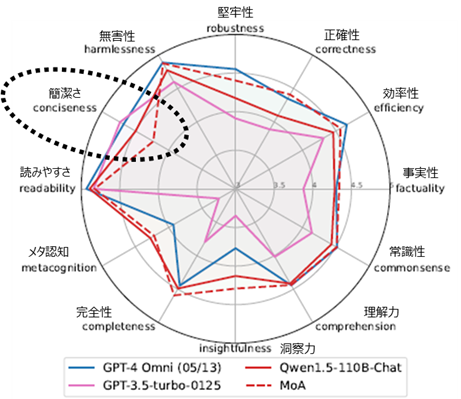
【図4】 MoA-FLASKの評価結果 (*1)
※論文記載の図にカテゴリ名(日本語)を追記
| カテゴリ名 | カテゴリの説明 |
|
堅牢性 |
・文法的な誤りやタイポに影響を受けることなく適切な回答を生成する能力 ・事前学習データに含まれない新しい概念等の知識要求などへの対応能力 |
|
正確性 |
・正解に近い回答を生成できる能力 |
|
効率性 |
・正解を得るまでに不要なステップを含まない(効率的)能力 |
|
事実性 |
・正確かつ文脈的に適切な応答を提供する能力 |
|
常識性 |
・常識に則った回答をする能力 |
|
理解力 |
・指示の暗黙的および明示的な目的と要件を理解する能力 |
|
洞察力 |
・指示に対する創造的な視点や解釈を開発する能力 |
|
完全性 |
・詳細かつ幅広い情報を提供することで指示を処理する能力 |
|
メタ認知Metacognition |
・指示に対する回答能力を認識する能力 |
|
読みやすさ |
・ユーザーの読みやすさを促進するための回答を構成するモデルの能力 |
|
簡潔さ |
・不要な情報を排除した簡潔な回答を提示する能力 |
|
無害性 |
・ユーザーの安全に対する潜在的なリスクを考慮する能力 |
*4 引用元:FINE-GRAINED LANGUAGE MODEL EVALUATION BASED ON ALIGNMENT SKILL SETS (https://arxiv.org/pdf/2307.10928)
汎用ローカルLLMを使用したMoAの構成例
公式よりコード(https://github.com/togethercomputer/moa)が公開されていますが、論文著者が所属する企業 ( Together AI )のAPIを利用することが前提の構成となっている
ため、ローカルLLMが利用できるようにコードを修正し、サンプル実行しました。
なお、今回は汎用ローカルLLMを使用してMoAを構成しました。
▍使用モデル
Hugging Faceから利用できるモデルのうち、日本語対応の軽量モデルを選択しました。
◎Proposer
| ●Qwen/Qwen1.5-0.5B-Chat |
| ●Qwen/Qwen2.5-0.5B-Instruct |
| ●meta-llama/Llama-3.2-1B-Instruct |
◎Aggregator
| ●meta-llama/Llama-3.2-1B-Instruct(Proposerとしても使用) |
※Llamaは制限モデルのため、Hugging Faceから利用の際はライセンスに同意して制限を
解除してください
▍環境例
◎Python 3.12
◎その他Lib関連:Dockerfileの例
▍コード実装例
論文公式コードにあるadvanced-moa.pyをベースに、LLM実行部分をローカルLLMが使用
できるよう修正しました。
◎修正コード(ローカルモデルの実行に必要な部分のみ記載)


▍MoA結果の遷移
Proposer層・Aggregator層で出てくる各LLMの回答の推移を記載しました。
各Proposerの回答は次の層に伝えられ、回答を見ると、情報が伝播していく様子が
見て取れます。
今回は環境上の都合により、かなり小さめのモデルのみ使用しましたが、Qwen1.5-72B-
Chatのようなもっと大きなサイズのモデルやある分野に特化したようなモデルを組み
込めれば、GPTの性能と同等、または、越える可能性も考えられます。
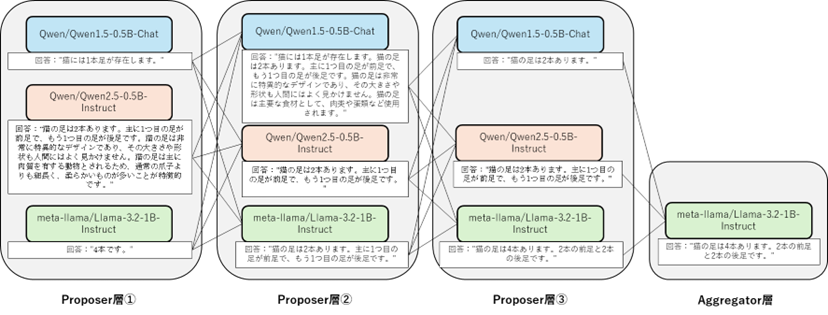
【図5】LLMの出力推移
まとめ
本記事では、Junlin Wang, 他が提案する「Mixture of Agents」(MoA)についてご紹介しました。
MoAは、複数の大規模言語モデル(LLM)を組み合わせて、各モデルの強みを活かしつつ、個々のモデルの弱点を補完する手法で、いくつかのバリエーション(コスト重視の「MoA-Lite」、デフォルト構成の「MoA」、高品質な出力を優先した「MoA w/ GPT-4o」)がありました。特に「MoA w/ GPT-4o」は、ユーザーの指示に従う能力やマルチターンダイアログでの会話能力で高いスコアを記録しました。ただし、MoAは従来のLLMに比べて、冗長な出力を生成する傾向もあり、簡潔さにおいては単体のLLMに劣る場合があります。
実際にローカルモデルを組み合わせてMoAを実行したところ、3B以下の軽量なモデルの組み合わせでGPT並みの回答が生成できることを確認しました。また、組み合わせるモデルの種類によってGPT以上の性能となる可能性も考えられます。
総じて、MoAは、複数のLLMを組み合わせることで、従来の単体LLMでは得られなかった性能向上を実現する新たなアプローチと言えるでしょう。
【参考文献】







お問い合わせ・
導入のご相談
AI導入や活用についての
ご質問・ご相談はこちらから。
現状の課題やお悩みをもとに、
最適な進め方をご提案します。
資料ダウンロード
調和技研の事業や事例集をご覧いただけます。
AI活用の全体像を知りたい方におすすめです。