
Segment Anything Model(SAM)を使いこなそう!パラメータ設定のポイントも徹底解説


こんにちは、皆さん!株式会社調和技研の研究開発部内の「画像系AI」グループにてお客様のAIの開発・導入支援を担当しています鈴木卓麻です。
今回は新しい画像セグメンテーション(画像を分析するとき、人、建物、車など、画像の中にある物体や領域を識別し分割すること)モデルとして注目されている『Segment Anything Model(以降SAM)』について調査した内容をご紹介します。
SAMとは?セグメンテーションのための基盤モデル
SAMは、Segment Anything Modelの略称で、Meta社が2023年4月5日に公開したセグメンテーションのための基盤モデル(foundation model)です。SAMを使用することで、ファインチューニングなしであらゆる物体のセグメンテーションを行うことができます。しかし、SAMの細かいパラメータ設定や使い方についての情報がまだ不足しています。そこで、SAMのパラメータや設定について調査してみました。
ちなみにセグメンテーションには下記の種類がありますが、最近はクラスの分類という概念が薄れ、どんなものでも検出するのがトレンドとなっており、SAMは下記のどれにも当てはまらない新しい手法と考えています。
- セマンティック・セグメンテーション(領域分類)
画像全体や画像の一部の検出ではなく、画像の各ピクセル(画素)に対して、そのピクセルがどのクラスに属するかを予測する手法
- インスタンス・セグメンテーション(個別物体領域分割)
画像内の各ピクセルをクラスに分類するだけでなく、それぞれの物体が個別の「インスタンス」であることを認識できる手法
- パノプティック・セグメンテーション(全体画像領域分割)
上記二つを組み合わせた手法。つまり、画像内のすべてのピクセルを適切なクラスに分類し(領域分割)、さらにその中の各個別の物体を識別(個別物体領域分割)する
SAMの公式サイト[1]のデモは研究目的のみに限定されていますが、SAMのコード自体はApache-2.0ライセンスの下で配布されており、このライセンスは商用利用を含む幅広い用途での使用を許可しています。つまり、SAMのコードや学習済みモデルは、商用プロジェクトに組み込んだり、商用製品の一部として使用したりすることが可能です。
ただし、Apache-2.0ライセンスには条件があり、ライセンスのコピーをコードとともに配布する必要があるなど、いくつかの要件を満たす必要があります。また、元の著作者や商標に関する注意事項を尊重する必要があります。これらの条件を遵守することで、SAMのコードや学習済みモデルを商用で安全に使用することができます。(2024年5月17日追記)
SAMでできること
SAMは上述の通り、あらゆる物体をセグメンテーションをしてくれます。しかもZero-shot(学習していない物体に対しての性能)でも高い性能を出すと元論文[2]で明言されています。

 使い方はシンプルです。
使い方はシンプルです。
環境構築+事前学習モデルのダウンロード(Linuxコマンドの場合)
pip install git+https://github.com/facebookresearch/segment-anything.git
pip install opencv
wget -q https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth実行コード
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator
sam = sam_model_registry[“vit_h”](checkpoint=“sam_vit_h_4b8939.pth”)
sam.to(device=“cuda”)
mask_generator_ = SamAutomaticMaskGenerator(model=sam)
import cv2
image = cv2.imread(filename)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
masks = mask_generator_.generate(image) 出力結果
masksは様々な情報を含むdictで返ってきます。詳細は以下の形式です。
|
項目 |
型 |
詳細 |
|
segmentation |
[np.ndarray] |
(W, H)の形状を持つマスクでbool型 |
|
area |
[int] |
マスクの面積(ピクセル) |
|
bbox |
[List[int]] |
xywhフォーマットのマスクの境界ボックス |
|
predicted_iou |
[float] |
マスクの品質に関するモデル自身の予測値 |
|
point_coords |
List[float]] |
このマスクを生成したサンプリングされた入力点 |
|
stability_score |
[float] |
マスクの品質に関する追加的な指標 |
|
crop_box |
List[int] |
このマスクを生成するために使用された画像のクロップ(xywh形式) |
[segmentation]
以下のようにオブジェクト毎に出力されます。bool型で出力されるため、画像にするにはuint8などにキャストする必要があります。

[area]
各マスクのピクセル数が返ってきます。例えば下図の場合188092pxです。

[bbox]
バウンディングボックス[x,y,w,h]で返ってきます。描画すると下図のイメージです。

[predicted_iou]
オブジェクトの信頼度といったところです。数値が高ければよいと考えてください。一般的には1.0がMaxですが、SAMだと1.0越えで返ってくることもあります。

[point_coords]
このマスクを生成したサンプリングされた入力点です。SAMを自動ではなく、手動で動かす場合は任意の点を指定することができます。

[stability_score]
こちらはSAM内部での独自の評価数値のようです。詳細は調べ切れていません。

[crop_box]
このマスクを生成するために使用された画像の切り出し座標です。自動の場合、画像全体が対象になるので(0、0、画像の幅、画像の高さ)になります。手動の場合は任意にこの矩形を選択することができます。

以上のように手軽にセグメンテーションを実行することができます。
SAMのパラメータ設定
SAMを効果的に活用するためには、パラメータ設定が重要です。現段階で確認できるパラメータは以下のものとなります。ソースコードに記載してあった説明を日本語に訳して載せています。
| パラメータの名称 | 型 | 説明 |
|
points_per_side |
int or None |
画像の片側に沿ってサンプリングされる点の数。総ポイント数はpoints_per_side2である。Noneの場合、’point_grids’が明示的に点サンプリングを行う必要がある。 ポイントサンプリングが必要である。 |
|
points_per_batch |
int |
モデルによって同時に実行される点の数を設定する。数値が高いほど高速になりますが、より多くのGPUメモリを使用します。 |
|
pred_iou_thresh |
float |
モデルの予測したマスク品質を使用した、[0,1]のフィルタリングの閾値です。 |
|
stability_score_thresh |
float |
[0,1]のフィルタリング閾値。モデルのマスク予測値を2値化するために使用されるカットオフの変化に対するマスクの安定性を使用する。 |
|
stability_score_offset |
float |
安定性スコアを計算する際にカットオフをシフトする量。 |
|
box_nms_thresh |
float |
重複したマスクをフィルタリングするために非最大限の抑制で使用されるボックスIoUのカットオフ値。 |
|
crop_n_layers |
int |
int: >0 の場合、マスク予測は画像のクロップで再度実行されます。実行するレイヤー数を設定し、各レイヤーは2i_layer数の画像クロップを持ちます。 |
|
crop_nms_thresh |
float |
異なるクロップ間で重複するマスクをフィルタリングするために、非最大限の抑制で使用されるボックスIoUカットオフです。 |
|
crop_overlap_ratio |
float |
クロップが重なり合う度合いを設定します。最初のクロップレイヤーでは、クロップは画像の長さのこの割合で重なります。より多くのクロップがある後のレイヤーでは、このオーバーラップは縮小されます。 |
|
crop_n_points_downscale_factor |
int |
レイヤーnでサンプリングされたサイドごとのポイント数をcrop_n_points_downscale_factor**nでスケールダウンします。 |
|
point_grids |
list(np.ndarray) or None |
[0,1]に正規化された、サンプリングに使用される点の明示的なグリッドを超えるリスト。リスト内のn番目のグリッドがn番目のクロップレイヤーで使用されます。points_per_sideと排他的である。 |
|
min_mask_region_area |
int |
0 以上の場合、min_mask_region_area よりも小さい面積のマスクの切断領域と穴を除去するための後処理が適用されます。opencv が必要です。 |
|
output_mode |
str |
マスクをどのような形式で返すか。binary_mask‘、’uncompressed_rle‘、’coco_rle‘のいずれかを指定することができる。coco_rle‘ は pycocotools を必要とする。大きな解像度の場合、’binary_mask‘は大量のメモリを消費する可能性がある。 |
これらのパラメータは、SAMのセグメンテーション結果や処理速度に影響を与えます。コードでは以下のように設定します。
mask_generator_ = SamAutomaticMaskGenerator(model=sam)mask_generator_ = SamAutomaticMaskGenerator(model=sam
points_per_side = 32,
pred_iou_thresh = 0.980,
stability_score_thresh = 0.96,
crop_n_layers = 1,
crop_n_points_downscale_factor = 2,
min_mask_region_area = 100,
)パラメータ設定のポイント
SAMのパラメータ設定にはいくつかのポイントがあります。特に今回は画像全体を自動でセグメンテーションする機能に絞って、注意すべきポイントをまとめました。
- points_per_sideの設定 → 検出精度の粗さをコントロール
- pred_iou_threshとstability_score_threshのバランス → 信頼度の低いオブジェクトを除去
- crop_n_layersの設定とクロップの重なり具合 → 重複検出を避ける
これらのポイントを理解して正しく設定することで、より精度の高いセグメンテーション結果を得ることができます。
パラメータ設定の具体例
上記に挙げたポイントについて、SAMのパラメータ設定の具体的な例を見てみましょう。各パラメータの適切な値や相互関係を理解するために、実際のケースを挙げて解説します。
1. points_per_sideの設定
画像を、この数値で分割した割合で検索します。今回はpoints_per_side=32と設定しているので、横32点、縦32点の1024点を探索し、その中から代表的な点を使い、マスクを生成します。

数値を下げると、この点数が減るため探索領域が粗くなります。数値を上げると逆に点数が増えるため探索領域が細かくなり、小さなオブジェクトも検出できる可能性が高まりますが、その分速度も遅くなります。そのあたりは目的に応じて設定をしてください。
2. pred_iou_threshとstability_score_threshのバランス
SAMでは検出したオブジェクト毎にpred_iou_threshとstability_score_threshのスコアが出力されます。そのスコアを閾値として、マスクとして出力するかしないかを制御することができます。
デフォルト設定pred_iou_thresh=0.88、カスタム設定pred_iou_thresh=0.98にした場合を比較してみましょう


このように、設定を調整することで出力をより信頼度の高いオブジェクトのみに絞ることができます。
逆にいえば、SAMに入れたが検出できないときは、この数値pred_iou_threshやstability_score_threshを下げることで検出できるようになるかもしれません。
3. crop_n_layersの設定
こちらは検出したオブジェクトを、もう一度切り取り、その領域を再検索するという設定です。
例えばですが、このように器二つが同じオブジェクトとして認識されました。(マスク画像と入力画像を乗算したものを表示しています。)
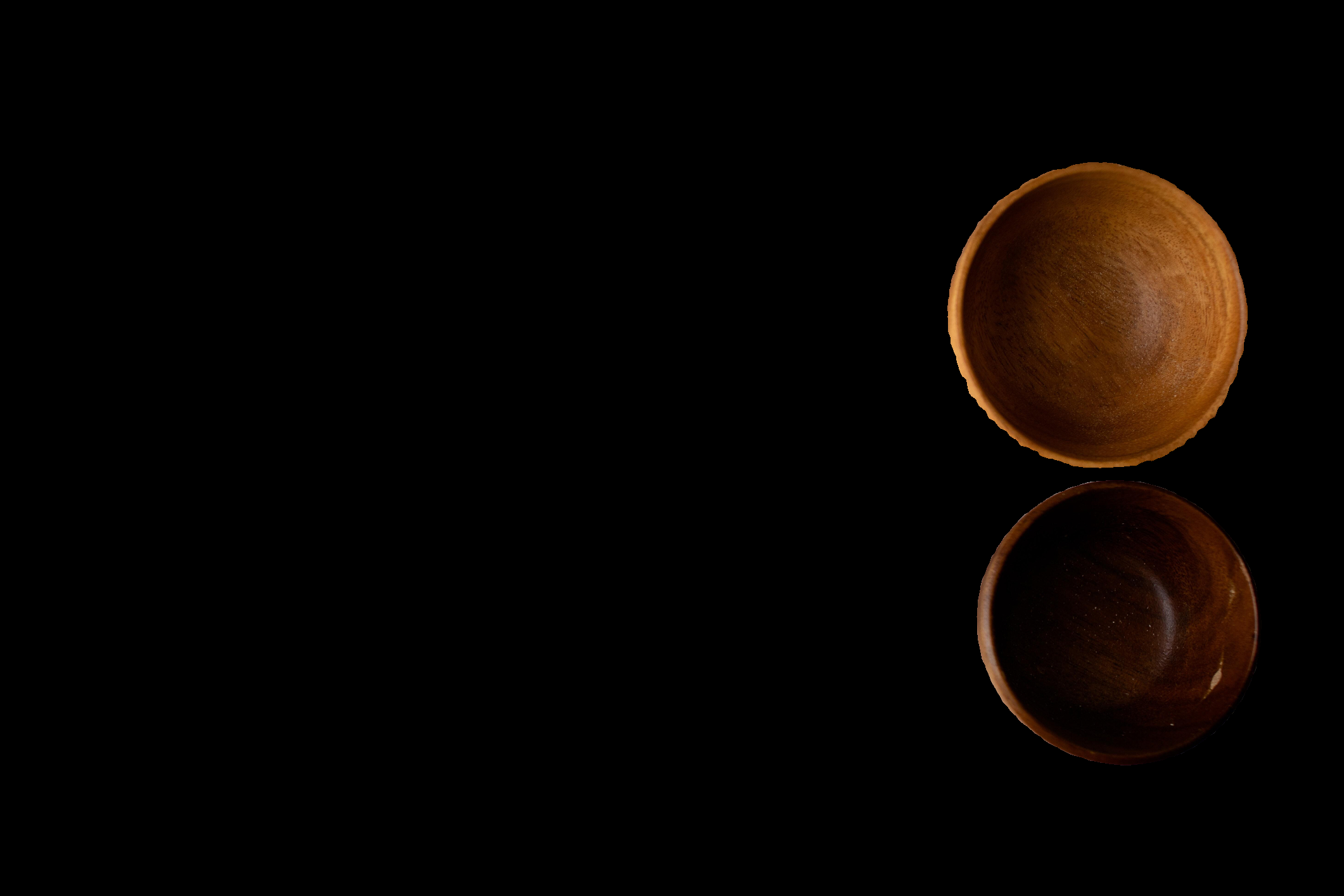
crop_n_layersが0より大きい場合、これを更に別オブジェクトとして検索してくれます。
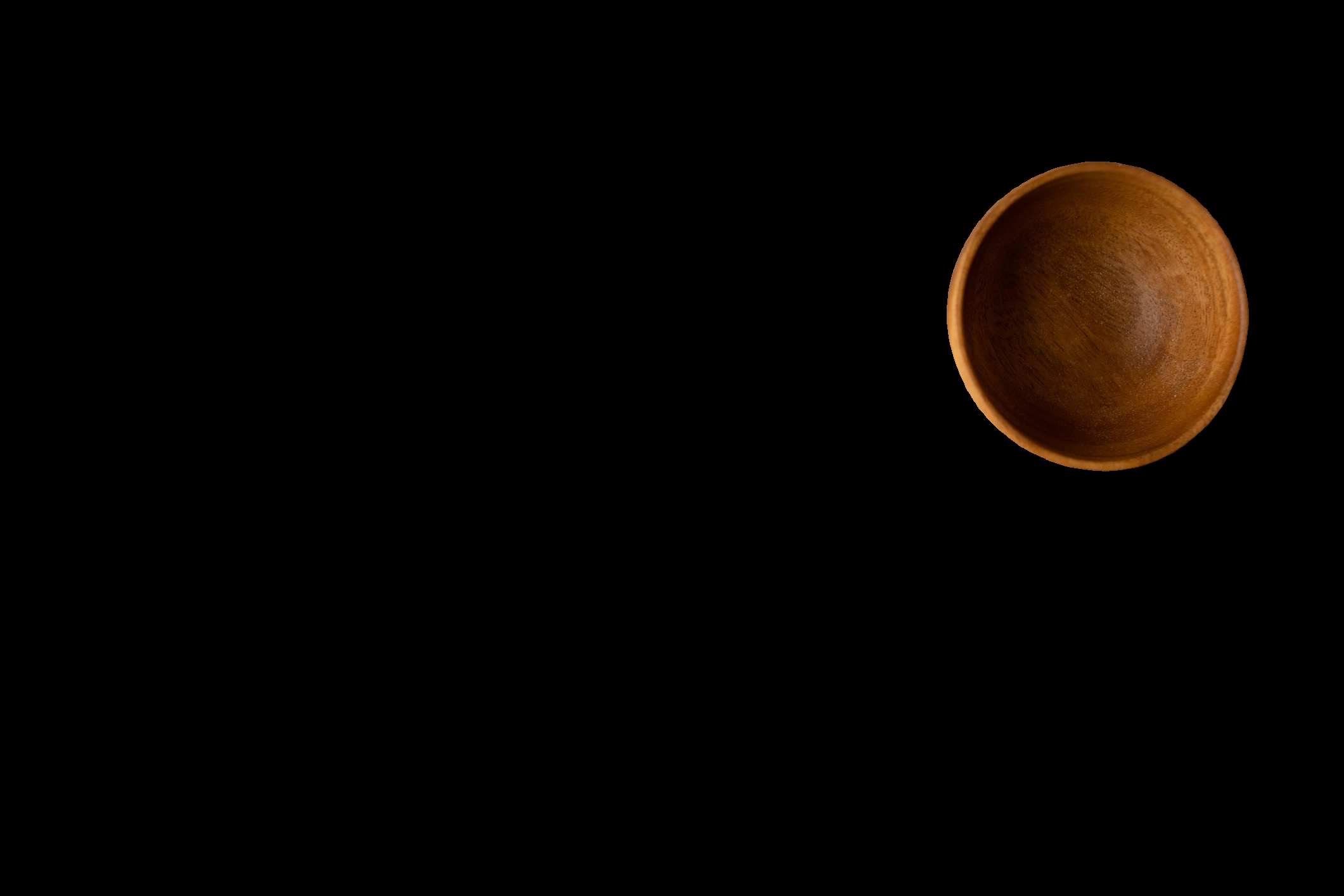

数値を増やすほど繰り返し分割してくれますが、その分、時間もメモリも大量に必要になるため多くてもcrop_n_layers=2に留めるのがよいと思います。
これらの要素を考慮しながら、最適なパラメータの値を調整していきましょう。
Gradioを使ってSAMによる簡易セグメンテーションツールを作成
GradioというPythonの機械学習モデルに対して、簡単にWeb UIを実装できるライブラリを使用してアプリケーション作ってみました。
Gradioは数行のコードで以下のようなインターフェースを用意してくれるため、私は愛用しています。
import gradio as gr
def segment(image):
pass # Implement your image segmentation model here...
gr.Interface(fn=segment, inputs="image", outputs="image").launch()今回は次の仕様にしました。この記事は今回ご紹介するコードをベースにパラメータ調査を行いました。調査しながらの作りなので、設計がいまいちな部分もあるかと思いますがその辺はご愛敬ということで…。
- 画像を読み込ませる。
- 送信ボタンを押したら、モデルが実行される。
- 右側に原画、セグメンテーション結果を原画にオーバーレイした画像、セグメンテーション画像を表示する
- パラメータを一部設定できるようにし、精度を調整できる。
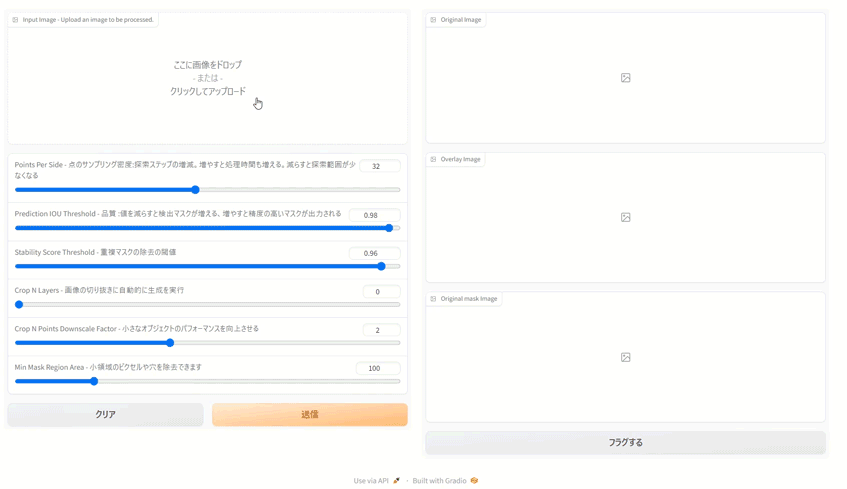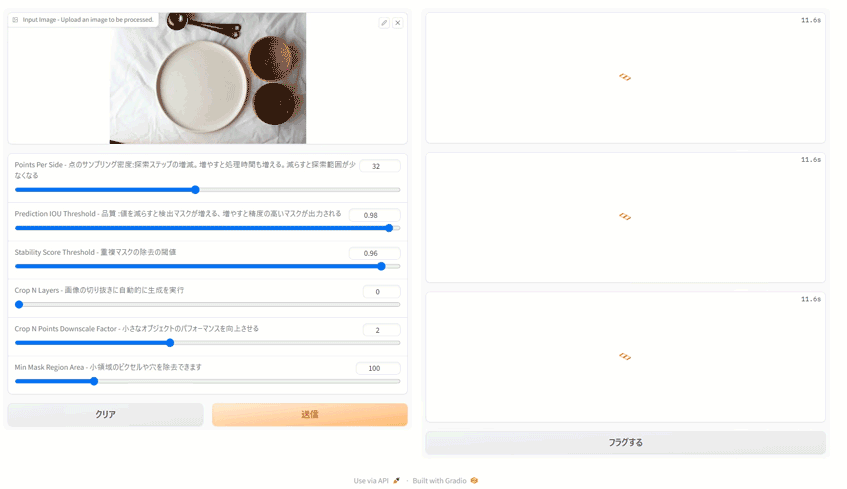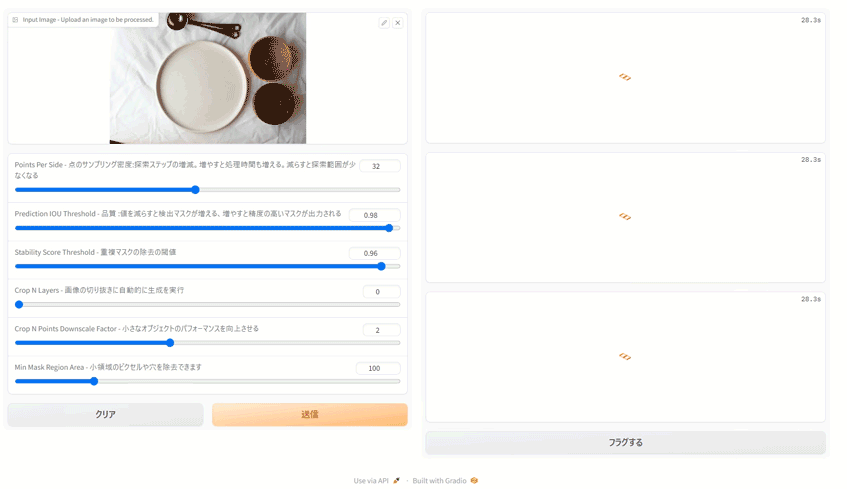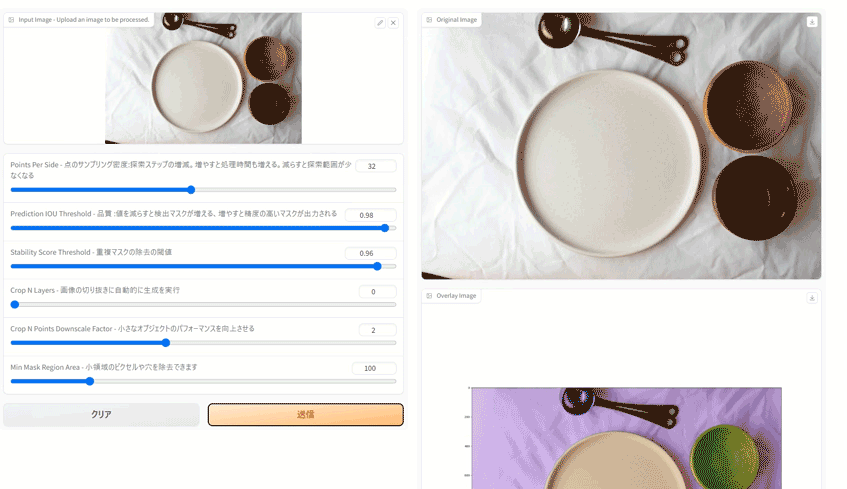
上記アプリのコードはこちらになります。
import os
import torch
import cv2
import sys
import gradio as gr
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import io
# Add the path of 'segment_anything' module to sys.path
sys.path.append("..")
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator
def create_directory(directory):
if not os.path.exists(directory):
os.makedirs(directory)
# MaskGenerator Class
class MaskGenerator:
# Initialize the class with model type, device, and checkpoint path
def __init__(self, model_type="vit_h", device="cuda", checkpoint_path=None):
self.model_type = model_type
self.device = device
self.checkpoint_path = checkpoint_path
self.model = None
self.mask_generator = None
# Load the model into the specified device
def load_model(self):
self.model = sam_model_registry[self.model_type](checkpoint=self.checkpoint_path)
self.model.to(device=self.device)
# Initialize the mask generator with the given parameters
def initialize_mask_generator(self, points_per_side, pred_iou_thresh, stability_score_thresh, crop_n_layers, crop_n_points_downscale_factor, min_mask_region_area):
self.mask_generator = SamAutomaticMaskGenerator(
model=self.model,
points_per_side=points_per_side,
pred_iou_thresh=pred_iou_thresh,
stability_score_thresh=stability_score_thresh,
crop_n_layers=crop_n_layers,
crop_n_points_downscale_factor=crop_n_points_downscale_factor,
min_mask_region_area=min_mask_region_area
)
# Generate masks, color them, and return them along with their counts
def generate_and_return_colored_masks(self, image):
masks = self.mask_generator.generate(image)
combined_mask = np.zeros_like(image)
np.random.seed(seed=32)
for i, mask_data in enumerate(masks):
mask = mask_data['segmentation']
mask = mask.astype(np.uint8)
random_color = np.random.randint(0, 256, size=(3,))
colored_mask = np.zeros_like(image)
colored_mask[mask == 1] = random_color
combined_mask += colored_mask
combined_mask_colored = combined_mask.copy()
combined_mask_colored[colored_mask > 0] = 0
combined_mask = np.clip(combined_mask, 0, 255)
combined_mask_3ch = cv2.cvtColor(combined_mask, cv2.COLOR_BGR2RGB)
return self.show_anns(image, combined_mask_3ch),combined_mask
# Display the masks on top of the original image
def show_anns(self, image, masks):
fig = plt.figure(figsize=(20,20))
image = cv2.cvtColor(np.array(image), cv2.COLOR_BGR2RGB)
image = cv2.addWeighted(image,0.7, masks,0.3,0)
plt.imshow(image)
plt.axis('on')
buf = io.BytesIO()
plt.savefig(buf, format='png')
buf.seek(0)
img = Image.open(buf)
return img
# Check the existence of the checkpoint file and other specifications
def check_status():
checkpoint_path = os.path.join("weights", "sam_vit_h_4b8939.pth")
print(checkpoint_path, "; exist:", os.path.isfile(checkpoint_path))
print("PyTorch version:", torch.__version__)
print("CUDA is available:", torch.cuda.is_available())
return checkpoint_path
# Function to process the image and generate masks
def process_image(image, points_per_side, pred_iou_thresh, stability_score_thresh, crop_n_layers, crop_n_points_downscale_factor, min_mask_region_area):
checkpoint_path = check_status()
org_image = image
image = cv2.cvtColor(np.array(image), cv2.COLOR_RGB2BGR)
mask_gen = MaskGenerator(checkpoint_path=checkpoint_path)
mask_gen.load_model()
mask_gen.initialize_mask_generator(points_per_side, pred_iou_thresh, stability_score_thresh, crop_n_layers, crop_n_points_downscale_factor, min_mask_region_area)
mask_image,combined_mask = mask_gen.generate_and_return_colored_masks(image)
return org_image,mask_image,combined_mask
# Main function to run the application
if __name__ == "__main__":
create_directory("images")
inputs = [
gr.inputs.Image(label="Input Image - Upload an image to be processed."),
gr.inputs.Slider(minimum=4, maximum=64, step=4, default=32, label="Points Per Side - 点のサンプリング密度:探索ステップの増減。増やすと処理時間も増える。減らすと探索範囲が少なくなる"), # points_per_side
gr.inputs.Slider(minimum=0, maximum=1, step=0.001, default=0.980, label="Prediction IOU Threshold - 品質 :値を減らすと検出マスクが増える、増やすと精度の高いマスクが出力される"), # pred_iou_thresh
gr.inputs.Slider(minimum=0, maximum=1, step=0.001, default=0.960, label="Stability Score Threshold - 重複マスクの除去の閾値"), # stability_score_thresh
gr.inputs.Slider(minimum=0, maximum=5, step=1, default=0, label="Crop N Layers - 画像の切り抜きに自動的に生成を実行"), # crop_n_layers
gr.inputs.Slider(minimum=0, maximum=5, step=1, default=2, label="Crop N Points Downscale Factor - 小さなオブジェクトのパフォーマンスを向上させる"), # crop_n_points_downscale_factor
gr.inputs.Slider(minimum=1, maximum=500, step=1, default=100, label="Min Mask Region Area - 小領域のピクセルや穴を除去できます"), # min_mask_region_area
]
gr.Interface(fn=process_image, inputs=inputs,
outputs=[gr.outputs.Image(type="pil",label="Original Image"),
gr.outputs.Image(type="pil",label="Overlay Image"),
gr.outputs.Image(type="pil",label="Original mask Image")
]
).launch()
最新技術も積極的に活用しよう
SAMは優れたセグメンテーションモデルですが、最大限に活かすためには、正確なパラメータ設定が必須となります。ちょっと複雑そうに感じるかもしれませんが、この記事を通じてSAMのパラメータや設定方法について深い理解を得ていただければ幸いです。SAMを使いこなし、セグメンテーション作業の効率化を実現しましょう!
※SAMの詳細なパラメータ設定や使い方については、公式GitHub[3]にあるサンプルコードを参照することをおすすめします。
調和技研の研究開発部では、SAMのような最新技術も積極的に研究・活用し、お客様に最適なソリューションを提供できるよう取り組んでおります。AIの活用や導入にお困りのことなどありましたら、いつでもお気軽にご相談ください。
【参考文献】
[3] GitHub – facebookresearch/segment-anything: The repository provides code for running inference with the SegmentAnything Model (SAM), links for downloading the trained model checkpoints, and example notebooks that show how to use the model.







お問い合わせ・
導入のご相談
AI導入や活用についての
ご質問・ご相談はこちらから。
現状の課題やお悩みをもとに、
最適な進め方をご提案します。
資料ダウンロード
調和技研の事業や事例集をご覧いただけます。
AI活用の全体像を知りたい方におすすめです。