

Stable Diffusionを使って異常画像データを生成できるか検証してみた

目次
初めまして、2023年に調和技研に新卒入社した神戸です。調和技研の研究開発部では、お客様に最適なソリューションをご提供できるよう、最新技術のキャッチアップや、その実用化に向けた検証に日頃から取り組んでいます。
今回はその一例として、異常品検出への「画像生成AI」の適用について検証を行った結果をご紹介します!
異常品検出における課題:異常データが少ない
AIを活用した異常品検出を導入する企業が近年増加しており、製造業や品質管理の現場で重要な役割を果たしています。
機械学習を用いて異常品検出を行う際は、正常品だけで学習を行い、学習データからのズレが大きいものを異常品として扱うことが一般的です。
一方、正常品だけで学習を行うことが難しい場合や、異常の具体的な分類を把握したい場合は、異常品を用いて学習する必要がありますが、多くのケースにおいて、異常品のデータはそもそも数が少ないという課題があります。そこで、AIを用いて異常品の画像を生成することで異常品のデータを増やすというアプローチが考えられます。この記事では、画像生成AI「Stable Diffusion」を用いて異常データの生成ができるかを検証することにしました。
画像生成AI「Stable Diffusion」とは
Stable Diffusionは、Diffusion Model(拡散モデル)をベースとしたtext-to-imageの画像生成モデルです。テキストを入力として、そのテキストに沿った画像を生成することができます。例えば、「サンタ風の犬」と入力すると、サンタ帽を被った犬が出力されます。Stable Diffusionは、オープンソースになったことで爆発的に広まり、様々な派生モデルが作られています。人物画像を生成するための派生モデルでは、アニメ風の画像を生成するものや、よりリアルな人物の画像を生成するものなどがあります。
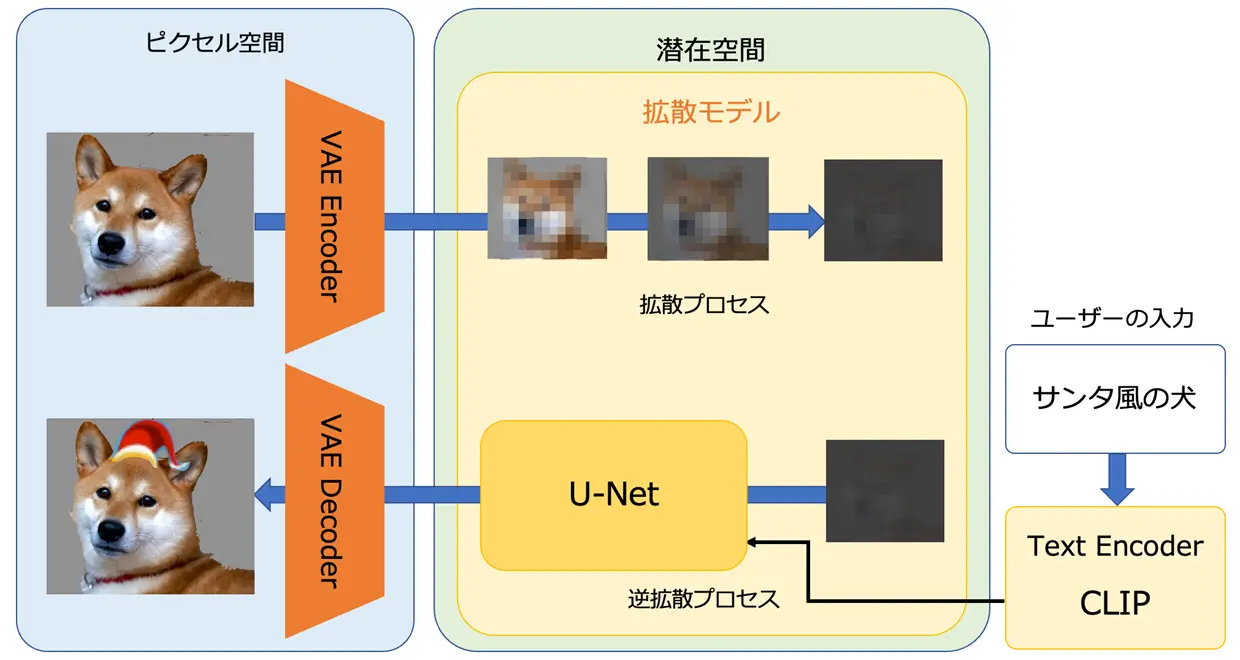
画像引用元:図で見てわかる!画像生成AI「Stable Diffusion」の仕組み
現在オープンソースとなっているStable Diffusionには、大きく分けてv1とv2が存在します。現在広く使われているのはv1で、これをベースにファインチューニングしたものが多いです。v2は2022年11月に登場しましたが、必ずしもv1よりも良い画像を生成できるという訳ではなく、生成する画像の種類によって得手不得手があります。2023年4月にはStable Diffusion XLが登場しました。このモデルは、7月中旬にオープンソースとして公開する予定でしたが、公開が延期され7/25日の時点で未だ公開されていません。
Stable Diffusionの活用方法
Stable Diffusionは、Webブラウザから操作できるようにした「Stable Diffusion web UI」を通じて利用できます。このツールは、モデルの変更も容易に行え、様々な拡張機能を用途に応じて使用することが可能です。具体的なセットアップ方法は、GitHubのリポジトリから確認できます。基本的にはGit cloneを行い、設定の記述を行うだけです。
本検証における諸条件
使用データ
データとしてはmvtecの異常検知データを用いました。このデータセットには、15種類のオブジェクトとテクスチャカテゴリに分類された5000枚以上の高解像度画像が含まれており、各カテゴリには、様々な種類の異常のある画像が含まれています。

画像引用元:MVTec Anomaly Detection Dataset: MVTec Software
今回の検証ではこの中から、ヘーゼルナッツデータを使用します。ヘーゼルナッツの中でも複数の異常がありますが、今回は「hole」を対象とし、正常データから穴が空いたヘーゼルナッツの画像を生成することを目指します。また、拡散モデルとしてはstable diffusion v1.5を使用しました。

検証した機能
異常データ生成をするために今回試した機能は以下の通りです。検証の第一弾として、追加学習を行う必要がないものに絞っています。
- img2img:画像をもとにして新しい画像を生成します。
- inpainting:画像の一部のみを修正します。
- instructpix2pix:文で編集を指示できる手法です。
- Stable Diffusion reimagine:入力画像に似た画像を生成します。
- reference only:画像を参照して同じキャラクター・絵柄などを追加学習なしで生成できます。
プロンプト
今回プロンプトエンジニアリングは行わずに、シンプルなプロンプトで試しました。Stable Diffutionにおけるプロンプトとは、画像生成を行う際に与えるテキストを指します。上で載せたStable Diffusionの概要図では、「サンタ風の犬」がプロンプトとなります。そして、プロンプトエンジニアリングとは与えるプロンプトを工夫することを指します。例えば、Stable Diffusionでは、イラスト調の画像を出力する際に”best quality”, ”masterpiece”, “ultra detailed”などをプロンプトに追加することで出力される画像のクオリティが上がることが知られています。
しかし、一般的に、求める出力を得るためのプロンプトエンジニアリングには多くの時間がかかります。更に、プロンプトエンジニアリングによって求める出力が確実に得られる保証もありません。Stable Diffusionがその概念を学んでいないことも十分考えられるからです。例えば、有名でないキャラクターや、一般的でない画角での画像などは学んでいない可能性が高いです。このため、今回はプロンプトエンジニアリングを行わずにシンプルなプロンプトでどれほどの精度が得られるか検証します。
今回の検証で試したプロンプトは以下の2つです。
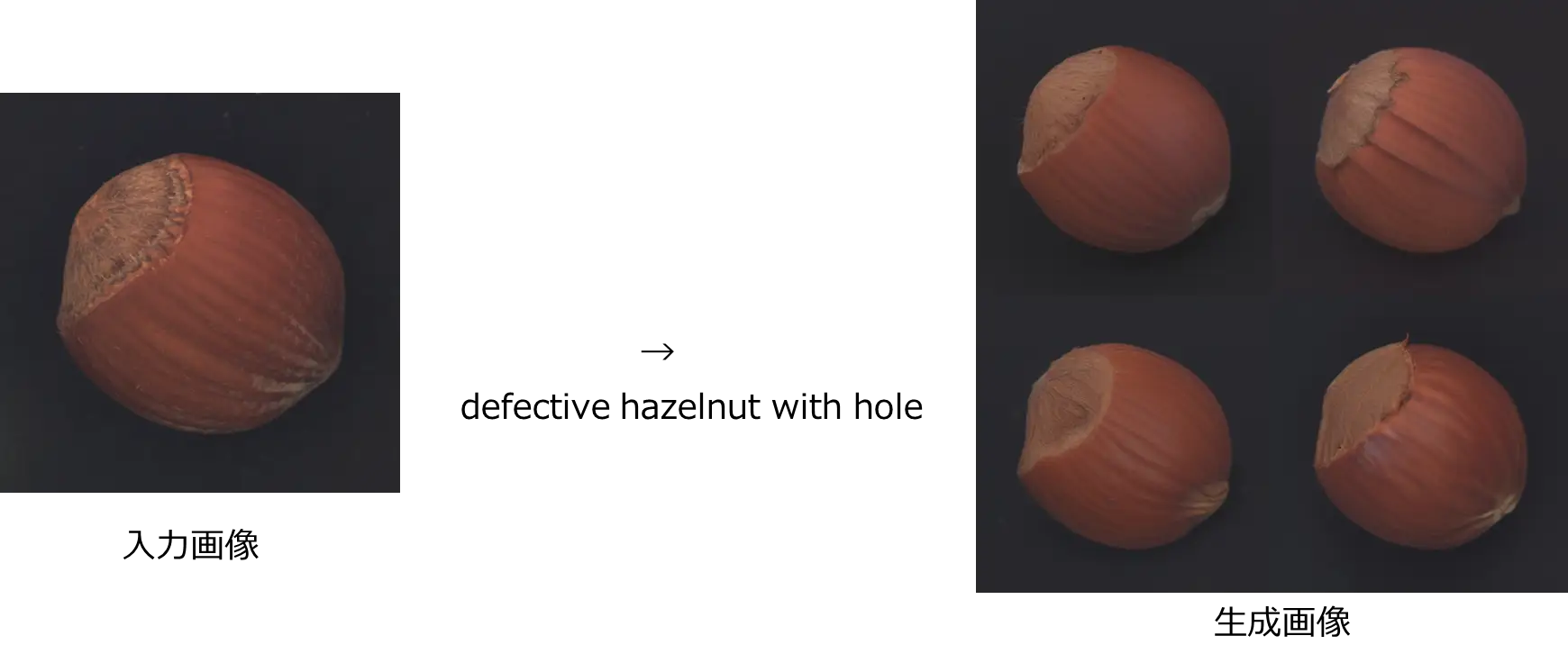
- defective hazelnut with hole
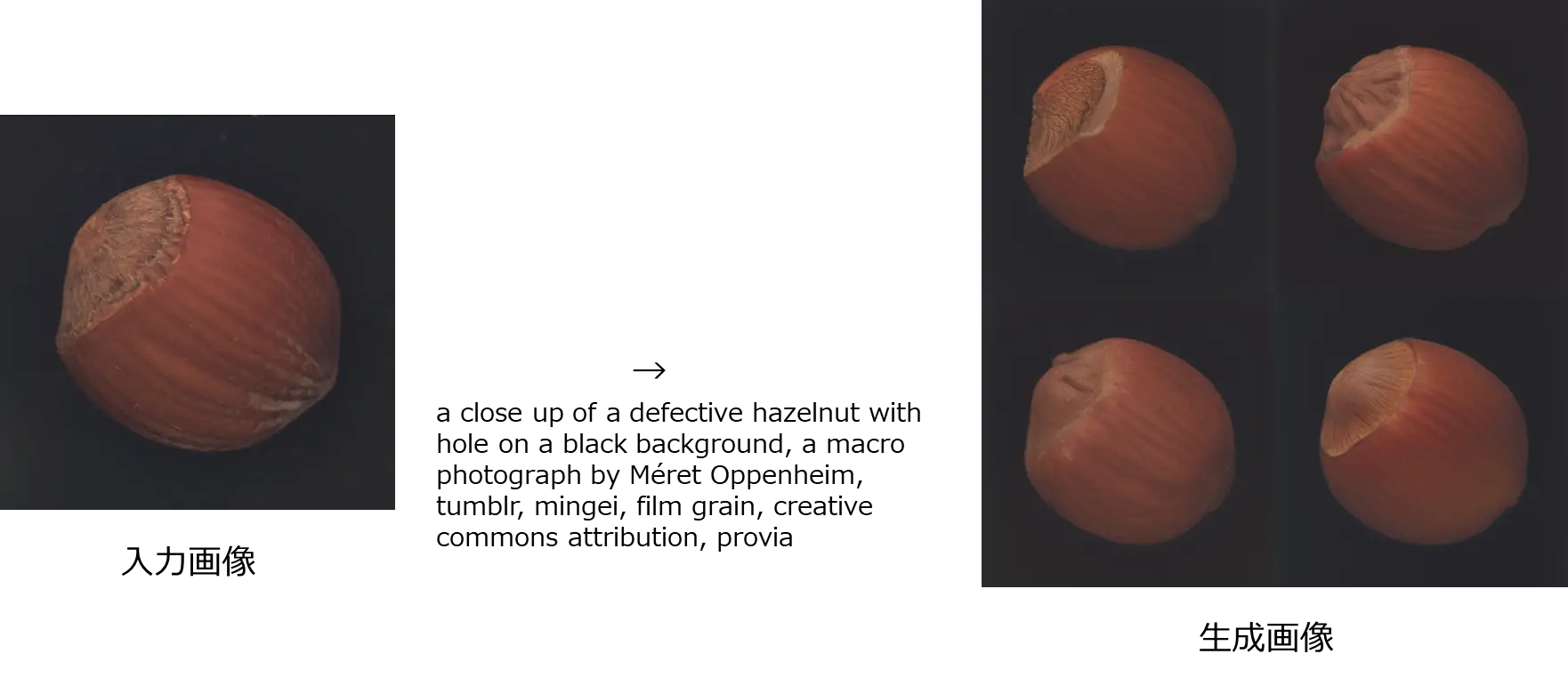
- a close up of a defective hazelnut with hole on a black background, a macro photograph by Méret Oppenheim, tumblr, mingei, film grain, creative commons attribution, provia
2つ目のプロンプトはimg2promptで出力したものです。 ヘーゼルナッツの画像を入力した時に出てきたプロンプトでorangeとなっていたのでそこだけdefective hazelnut with holeとして使用しました。
Stable Diffusionを用いた異常画像生成の結果
img2img
img2imgは入力画像とプロンプトをもとに画像を生成できる機能です。文字では説明の難しい具体的な構図やデザインなどは画像を用いて指定することができます。
画像引用元:stability-ai/stable-diffusion-img2img
Img2imgでの生成結果は以下のとおりです。


プロンプト通りの画像かもしれませんが、元の写真のイメージとは大きく離れてしまいました。
そこで、元の写真との乖離が小さくなるようにDenoising strengthというパラメータをいじってみます。これは、0~1の入力をとり、数字が小さいほど元画像を強く維持するようになります(0だと入力画像そのまま)。
デフォルトではこのパラメータは0.75となっているのでこれを0.3にしてみます。
元画像を反映していますが、今度は穴が開かなくなってしまいました。
img2imgでは、異常データの生成は難しそうです…。
inpainting
Inpaintingはimg2imgの一種で、画像の一部のみを修正できる機能です。画像内の余分なものを消す、写っている物体を別のものに変える、一部分のみ再生成する、といったことができます。画像上では犬のいる部分のみを修正して犬を消しています(あまり精度はよくありませんが…)。
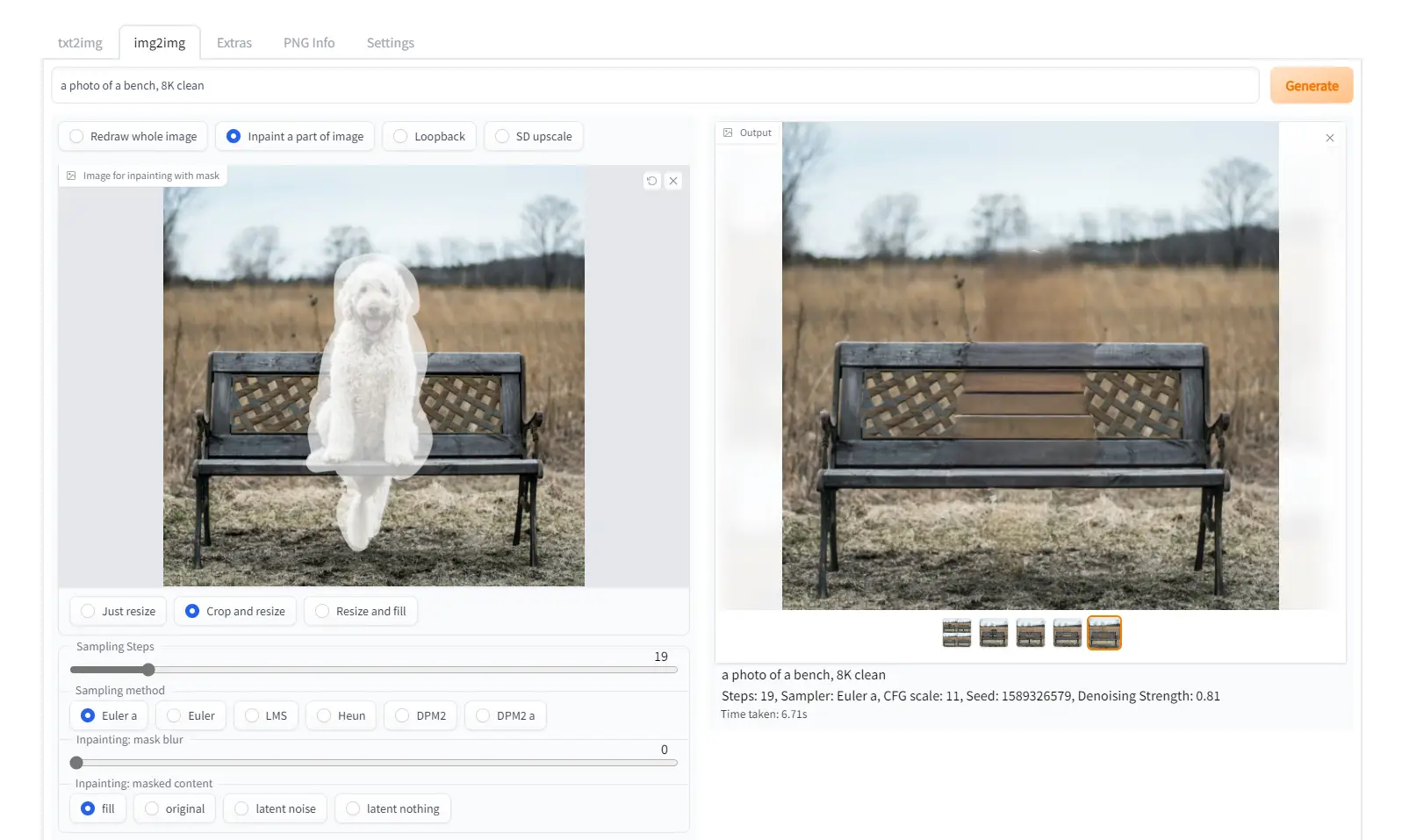
画像引用元:Features · AUTOMATIC1111/stable-diffusion-webui Wiki
Txt2imgで画像を生成し、うまく描写できなかった部分をinpaintingで生成し直すといった使い方が多いようです。このため、inpaitingのプロンプトにはTxt2imgの際に使用したプロンプトを再利用するのが一般的なようですが、今回はTxt2imgで生成していないためimg2imgの時と同じプロンプトを使用します。Inpaintingでは、画像の一部分のみを修正するため、元画像を維持しつつ変化することが期待できます。
生成結果は以下のとおりです。黒で塗りつぶした部分にinpaintingが適用されています。


穴自体はあいているものの不自然な穴になってしまっています。
そこで、masked contentというパラメータをいじってみます。これは、マスクの渡し方を指定するもので、下記の4つが用意されています。
- fill:元画像をぼかした状態で初期化
- original:そのまま
- latent noise:fillで初期化して潜在空間でノイズ付与
- latent nothing:ノイズ付与以外はlatent noiseと同じ
テキストだけではわかりにくいかも知れませんが、画像を見ればどのようにマスクが初期化されるかわかりやすいと思います。
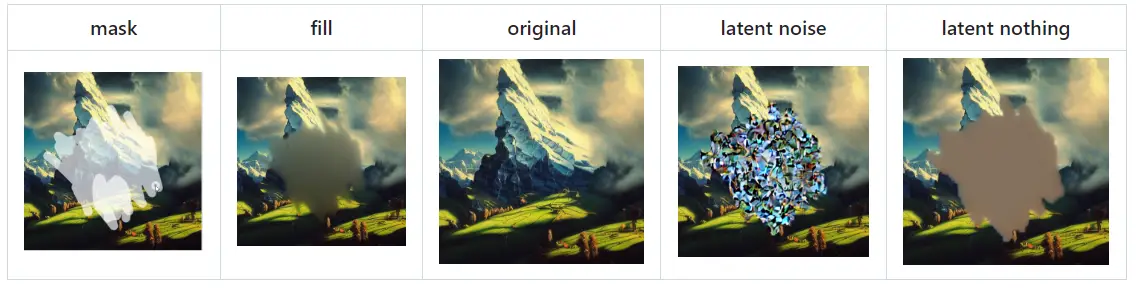
画像引用元:Features · AUTOMATIC1111/stable-diffusion-webui Wiki
デフォルトではoriginalですが、新しい物体を作るにはlatent noiseにするのが良いみたいなので、latent noiseにしてみます。
生成結果は以下のとおりです。


Masked contentがoriginalの時よりは良くなっていますが、それでも不自然な穴となってしまっています。
なお、ここまでの例で実際の画像上の穴と比べてマスクが大きすぎると思った方がいるかもしれませんが、これは、マスクを小さくして生成を行うとまったく変化がおきなかったためです。

Inpaintingでは、ある程度望む方向に画像を変化させることができました。しかし、百発百中ではないので、欲しい画像が出るまで生成を繰り返す、所謂”ガチャ”が必要であったり、大きな変化は起こせるが微細な変化は難しいといったことがわかりました。
instruct-pix2pix
instruct-pix2pixは文章で画像の編集を指示できる拡張機能です。通常のimg2imgでは、出力する画像をプロンプトで表現しますが、instruct-pix2pixでは入力画像からの差分をプロンプトで表現します。例えば、「ひまわりをばらに変える」といった指示で元画像の雰囲気を保ったまま画像内のひまわりをバラに変化させることができます。

画像引用:GitHub - timothybrooks/instruct-pix2pix
パラメータの設定はオリジナルのリポジトリと同等にし、denoisingを1.0、samplerをEuler a samplerにしました(参考)。また、プロンプトはシンプルに”make a tiny hole in it”としました。
生成結果は以下のとおりです。

色調が変化し、全体の雰囲気が大きく変わってしまいました。
instruct-pix2pixはinpaintingでも使用できるのでinpaintingも試してみます。
 通常のinpaintingとあまり変わりませんでした。Instruct-pix2pixの修正前後のデータセットはStable Diffusionで作っているようなので、似た結果になるのは当然なのかも知れません。
通常のinpaintingとあまり変わりませんでした。Instruct-pix2pixの修正前後のデータセットはStable Diffusionで作っているようなので、似た結果になるのは当然なのかも知れません。
Stable Diffusion Reimagine
Stable Diffusion Reimagineは、入力画像に似た画像を生成できる機能です。以下の画像例では、左上が入力画像で、他の3点は生成された画像です。

画像引用:Stable Diffusion Reimagine リリース
この方法では、正常画像から異常画像を作成することは出来ません。しかし、正常な画像からは別の正常な画像を、異常な画像からは別の異常な画像を生成することは可能なはずです。
生成結果は以下のとおりです。(Reimagine XL で試しました。)

元の画像から大きく離れた画像が生成されてしまいました。
reference only
reference onlyは、参照画像を基にして同じキャラクター・絵柄などを追加学習無しで生成できる機能です。
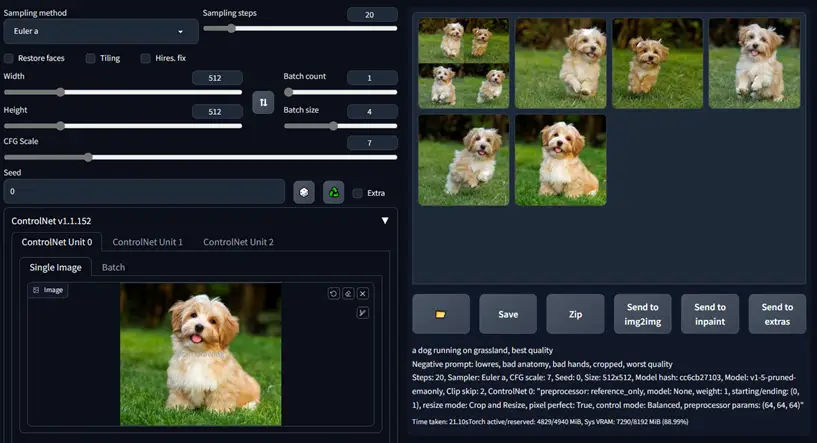
画像引用:GitHub - Mikubill/sd-webui-controlnet: WebUI extension for ControlNet
当然ではあるのですが、使用モデルに参照画像と同等の画像を生成する能力がなければうまく生成できないので、この点は注意が必要です。
この方法では、参照画像として異常データを与えました。また、”preprocessor”, “control mode”のパラメータをいじりました。今回は一番うまくいった ”preprocessor”を”reference_adin+attn”に、 “control mode”を”ControlNet is more important”にする組み合わせのみを掲載します。
生成結果は以下のとおりです。

色は少し薄いですが、かなり雰囲気が似た画像が生成できていることがわかります。もちろんガチャは必要ですが、今回試した中ではもっとも良い結果になりました。
AIによる異常検知なら調和技研にご相談ください!
今回は追加学習なしで異常データの生成ができるかを試みました。その結果、reference onlyでは実用化の可能性がありそうだということがわかりました。しかし、reference onlyでも広範囲で変化が起きているので、細かい箇所のみ異なるような異常データの生成は難しそうでした。
今後は、今回試みなかったLoRAなどを用いた追加学習や、異常品検出の学習に生成データを利用するなど、その実用性をさらに詳しく検証していきたいと思います。
調和技研では、異常検知に関する独自のAIエンジンを開発するなど(プレスリリース)、多くの企業様をご支援してきた実績やノウハウがあります。異常検知に関してお困りのことなどがありましたら、ぜひお気軽にご相談ください!

記事を書いた人
神戸 瑞樹
2023年に北海道大学を卒業し、調和技研に入社。大学では、服飾の印象をAIを用いて予測する研究を行っていました。現在は画像系AI開発に従事しながらリモートワークの快適さを享受しています。
関連記事

Stable Diffusion+LoRAを使って異常画像データを生成できるか検証してみた

大規模言語モデルによるソースコード生成:GitHub CopilotからCopilot Xへの進化と未来

AI導入の前に知っておくべき基礎知識(後編)――効率的に自業務にAIを導入するための4ステップ

配達ルート最適化AIにより作業時間80%削減を実現。成功の鍵は“人とAIの調和”

AI画像生成の法的リスク(後編):著作権侵害を回避するために

AI画像生成の法的リスク(前編):著作権法の基本を学ぼう

AI導入の前に知っておくべき基礎知識(前編)――AIのキホンと活用事例

CNNで浮世絵画風変換はできるのか――Ukiyolator開発ストーリー Vol.2

住宅写真という資産をAIで利活用し、工務店とお客様をつなぐ新たなビジネスを創造

シフト最適化への応用が期待される強化学習を用いた組合せ最適化の解法

多彩なサービスと紐づく「交通」の課題解決で地域の活性化や住みやすさの向上を【調和技研×AIの旗手 Vol.2】

AIプロダクトを開発する際に考えるべき品質保証のキホン

Microsoft GuidanceでのFunction Calling機能の使い方とその特徴

Segment Anything Model(SAM)を使いこなそう!パラメータ設定のポイントも徹底解説

基礎から解説!数値系異常検知の概要と代表的な手法

実践!ChatGPT×Slackの具体的な連携方法と日常業務での効果的な活用事例

最先端AI技術で浮世絵を現代に再現する――Ukiyolator開発ストーリー Vol.1

PaDiMとPatchCoreどちらを選ぶべき?異常検知モデルの選択肢を見極めるポイント

社内の暗黙知を可視化するナレッジネットワークでイノベーションが生まれやすい環境に
